Pomocí souboru Sitemap můžete poskytnout informace o stránkách, videích, obrázcích a dalších souborech na webu a vztazích mezi nimi.
Vyhledávače, jako je Google, po přečtení tohoto souboru mohou váš web procházet inteligentněji.
Google se ze souboru Sitemap dozví, které soubory na svém webu považujete za důležité, a také z něj o těchto souborech získá hodnotné informace.
O stránkách se například informuje, kdy byly naposledy aktualizovány, jak často se mění a jaké mají alternativní verze.
Pomocí souboru Sitemap můžete poskytnout metadata o konkrétních typech obsahu na stránkách, včetně videí a obrázků.
Základní kód XML dokumentu Sitemap může mít tento zápis:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://www.vasedomena.cz/stranka.html</loc>
<lastmod>2020-06-04</lastmod>
</url>
</urlset>
Pro podrobnou specifikaci mapy stránek můžete navštívit stránky zastřešující autority sitemaps.org.
V čem je sitemapa užitečná
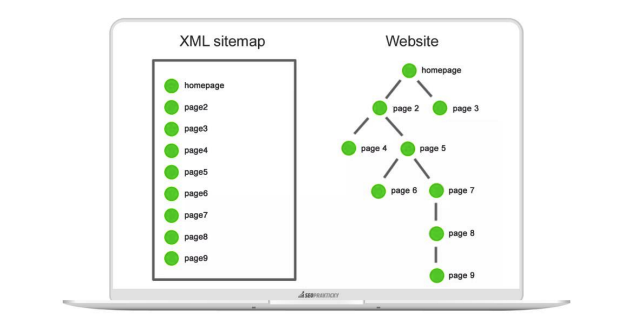
Na obrázku níže můžete vidět, jak sitemapa usnadní cestu vyhledávacím robotům.
Na níže uvedeném příkladu najde vyhledávací bot všech devět stránek v souboru Sitemap s jednou návštěvou souboru Sitemap XML.
Na webu bude muset přeskočit pět interních odkazů, aby našel stránku 9.
Potřebují stránky sitemapu?
Pokud jsou stránky vašeho webu správně propojeny pomocí odkazů, dokáže Google obvykle většinu webů objevit.
Procházení větších či složitějších webů nebo specializovaných souborů však soubor Sitemap přesto může vylepšit.
Sitemap budete potřebovat, když:
- Web je opravdu velký. V důsledku toho je pravděpodobnější, že by prohledávače Googlu mohly některé z vašich nových nebo nově aktualizovaných stránek přehlédnout.
- Web obsahuje rozsáhlý archiv stránek s obsahem, které jsou izolovány nebo navzájem nejsou dobře propojeny. Pokud na sebe stránky webu navzájem přirozeně neodkazují, můžete je uvést v souboru Sitemap, aby Google žádnou z nich nepřehlédl.
- Web je nový a směřuje na něj málo odkazů. Googlebot a ostatní prohledávače web procházejí tak, že následují odkazy z jedné stránky na jinou. Pokud na vaše stránky neodkazují žádné jiné weby, Google by je nemusel objevit.
- Web obsahuje mnoho multimediálního obsahu (videa, obrázky) nebo se zobrazuje ve Zprávách Google. Ve vhodných případech může Google při vyhledávání vzít v úvahu dodatečné informace ze souborů Sitemap.
Sitemap nebudete potřebovat, když:
- Váš web je malý. Za malý web se považuje web s maximálně 500 stránkami.
- Stránky vašeho webu jsou vzájemně propojeny odkazy. To znamená, že Google všechny důležité stránky na vašem webu dokáže najít sledováním odkazů z domovské stránky.
- Nemáte velký počet mediálních souborů (videa, obrázky) ani zpravodajských stránek, které chcete zahrnout do indexu. Soubory Sitemap mohou Googlu pomoci najít soubory videí a obrázků či zpravodajské články a porozumět jim, pokud chcete, aby se zobrazovaly ve výsledcích Vyhledávání Google. Pokud nepotřebujete, aby se tyto výsledky zobrazovaly ve výsledcích vyhledávání obrázků, videí nebo zpráv, soubor Sitemap pravděpodobně není nutný.
Formáty Sitemap
Vyhledávače podporují několik typů Sitemap, u všech je pak nutné, aby měly standardní protokol definovaný organizací sitemaps.org.
Mezi podporované formáty patří:
- XML
- RSS, mRSS a Atom 1.0
- Text
- Sitemapy generované z webů Google (vytvořených pomocí služby Weby Google)
Limity Sitemap a Sitemap Index
Ve všech formátech je každý soubor Sitemap omezen nezkomprimovanou velikostí 50 MB a počtem 50 000 adres URL. Máte-li větší soubor nebo více adres URL, budete seznam muset rozdělit do několika souborů Sitemap.
Volitelně můžete vytvořit index souborů Sitemap (soubor, který odkazuje na seznam souborů Sitemap) a odeslat do Googlu jeden index souborů Sitemap.
Do Googlu můžete odeslat několik souborů Sitemap nebo několik indexů souborů Sitemap.
Soubory Sitemap lze komprimovat pomocí gzip (název souboru vypadal např. nějak takto: sitemap.xml.gz). Komprimuje se z toho důvodu, aby se ušetřila data a zatížení serveru nutné k přenosu sitemapy.
Jakmile však soubor rozbalí, soubor Sitemap stále nemůže překročit ani jeden výše uvedený limit.
Kdykoli překročíte některý z limitů, budete muset rozdělit své adresy URL do několika souborů XML.
Jak se vyhledávače dozví o sitemapě
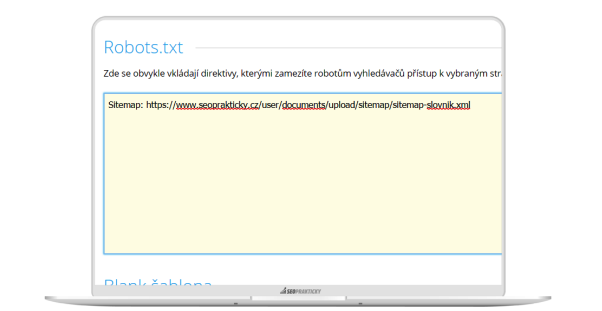
Crawleři se o sitemapě dozví buď z robots.txt (platí pro všechny boty), nebo z konzole (v případě botů společnosti Google).
Robots.txt
Odkaz na sitemapu se standardně přidává do robots.txt (viz kapitola Robots.txt).
Syntaxe je následující:
User-agent: *
Sitemap: https://www.vasedomena.cz/sitemap.xml
Google Search Console
Pokud používáte Google Search Console, což důrazně doporučuji, můžete odkaz na mapu stránek, obrázků nebo videí přidat přímo do konzole. Pak odkaz na sitemapu není důležitý pro Google, nýbrž pro ostatní vyhledávače zcela určitě. Proto odkaz na sitemapu v robots.txt vždy uvádějte (máte-li ji a má-li u vašeho projektu smysl).
V levé části klikněte na Soubory Sitemap a následně přidejte pouze stránku, na které je mapa stránek. V případě Shoptetu je to „sitemap.xml“.
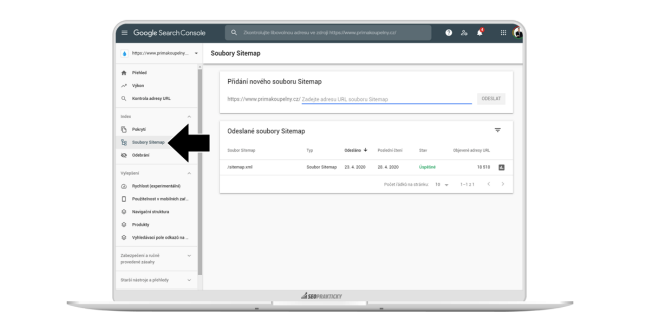
Jakmile konzole soubor zpracuje, můžete se podívat, kolik stránek ze sitemapy je již zahrnuto v indexu a kolik stránek na zahrnutí teprve čeká.
Jde-li vše tak, jak má, postupem času by vám měl růst počet zaindexovaných stránek jako na obrázku níže.
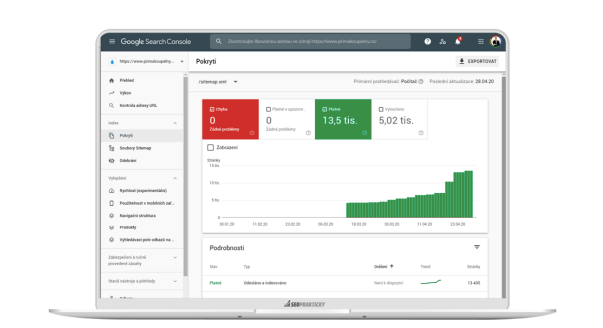
Na druhou stranu by vám měly ubývat vyloučené stránky, které Google postupně prochází a indexuje.
Přesouvají se tak ze stavu Procházeno – momentálně neindexováno a Objeveno – momentálně neindexováno do chtěného stavu Odesláno a indexováno.
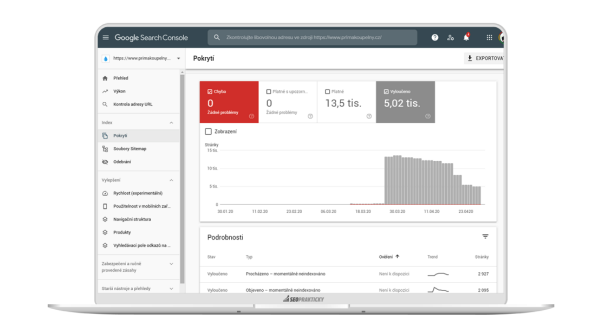
Do konzole můžete odeslat samostatnou mapu stránek nebo tzv. Sitemap Index, což je soubor, který odkazuje na několik dalších map stránek.
Sitemap Index se používá pro rozsáhlé projekty, které by jinak překročily limity pro standardní sitemapu.
Urychlení deindexace prostřednictvím sitemapy
V některých situacích můžete sitemapu využít i opačně než obvykle.
Budete-li chtít rychleji odebrat nějaké stránky z indexu vyhledávačů, můžete přidat stránky s direktivou noindex do sitemapy, a tím uspíšit jejich odebrání z databáze vyhledávačů.
Standardně se do sitemapy dávají pouze stránky, které jsou originální (kanonické) a jež chceme indexovat.
Jazykové a regionální varianty URL v sitemapách
O všech jazykových a regionálních variantách adres URL můžete Google informovat pomocí souboru Sitemap.
Provedete to přidáním prvku <loc> pro jednu adresu URL s podřízenými položkami <xhtml:link> pro každou jazykovou nebo regionální verzi stránky včetně stránky samé.
Pokud tedy máte tři verze stránky, bude soubor Sitemap obsahovat tři položky a každá z nich bude mít tři identické podřízené položky.
Syntaxe v Sitemap xml by byla následující:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:xhtml="http://www.w3.org/1999/xhtml">
<url>
<loc>http://www.example.com/english/page.html</loc>
<xhtml:link
rel="alternate"
hreflang="de"
href="http://www.vasedomena.com/deutsch/page.html"/>
<xhtml:link
rel="alternate"
hreflang="de-ch"
href="http://www.vasedomena.com/schweiz-
deutsch/page.html"/>
<xhtml:link
rel="alternate"
hreflang="en"
href="http://www.vasedomena.com/english/page.html"/>
</url>
</urlset>
Podrobnější informace o přípravě Sitemap pro vícejazyčný web najdete na stránce oficiální nápovědy Search Console Informujte Google o lokalizovaných verzích své stránky.
Ping na sitemapu
Pokud chcete, aby Google navštívil vaši sitemapu co nejdříve, můžete o takovou návštěvu manuálně požádat pomocí funkce ping.
Stačí odeslat požadavek HTTP GET podobný tomuto:
http://www.google.com/ping?sitemap=<úplná_adresa_url_souboru_sitemap>
Příklad:
http://www.google.com/ping?sitemap=https://vasedomena.cz/sitem
ap.xml
Použití této funkce je však ojedinělé. Google na vaše stránky bude přistupovat sám a není obvykle zvláštní důvod ho k tomu jakkoliv vybízet.
Sitemapa v Shoptetu
Sitemapa pro e-shopy na Shoptetu se generuje automaticky. Nemusíte se o nic starat, nic aktivovat.
Silně doporučuji navést odkaz na sitemapu do Google Search Console, což jsem zmínil v předchozí části.
Pokud používáte doplněk Slovník pojmů, který má stovky až tisíce výrazů, pak bych doporučil vygenerovat manuálně sitemapu i pro tuto část stránek, která ve standardní sitemapě bohužel chybí.
Pokud ve slovníku řešíte jen pár termínů (řádově desítky), nemusíte s mapou ztrácet čas. Crawleři stránky projdou pomocí odkazů ze stránek.
Níže uvedený postup je aplikovatelný i pro všechny správce stránek, kteří nemají mapu stránek generovanou automaticky.
Vygenerování sitemap pro slovník pojmů v programu Screaming Frog SEO Spider
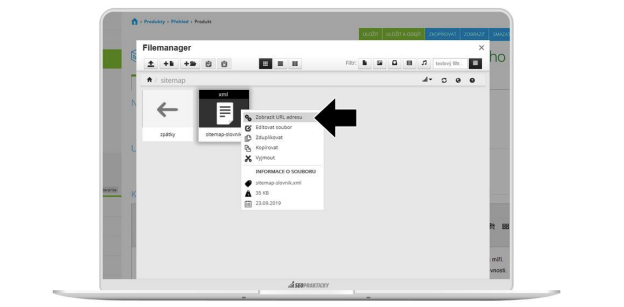
Provedete crawling celých stránek. Poté si vyfiltrujete pouze ty stránky, které obsahují část URL „slovnik-pojmu“, zbytek stránek smažete.
To můžete udělat tak, že si URL seřadíte vzestupně a URL nad a pod stránkami se slovníkem pojmů smažete.
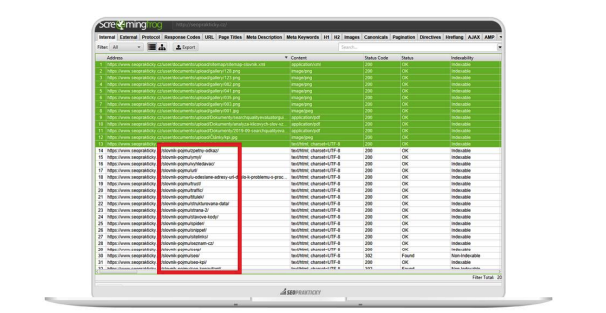
Poté z horní nabídky vyberete Sitemaps → XML sitemaps → Next. Do počítače se vám uloží nová mapa stránek, kterou si můžete pojmenovat např. sitemap-slovnik.xml.
Stránku si pak uložíme do jakéhokoliv adresáře v galerii souborů. Odkaz na soubor pak vložíme do Google Search Console. Následně si můžeme odkaz na soubor vložit i robots.txt.