
Ať už v Collabimu připravujete nový projekt, nebo jen revidujete stávající – je dobré začít základním technickým auditem stránek.
Protože než se případně pustíte do samotného obsahu, vyplatí se zkontrolovat, zda jsou stránky vůbec indexované a jestli na nich není nějaký problém technického rázu. Na stránkách, které nejsou zaindexované, by totiž optimalizace obsahu byla v zásadě zbytečná. A kromě toho můžete eventuálně objevit i jiné vady na kráse.
Osnova
Vstupní data pro analýzu
Pro základní ověření technického stavu stránek můžete použít analýzu URL. Tu najdete v hlavičce aplikace v sekci Analýzy a nástroje.
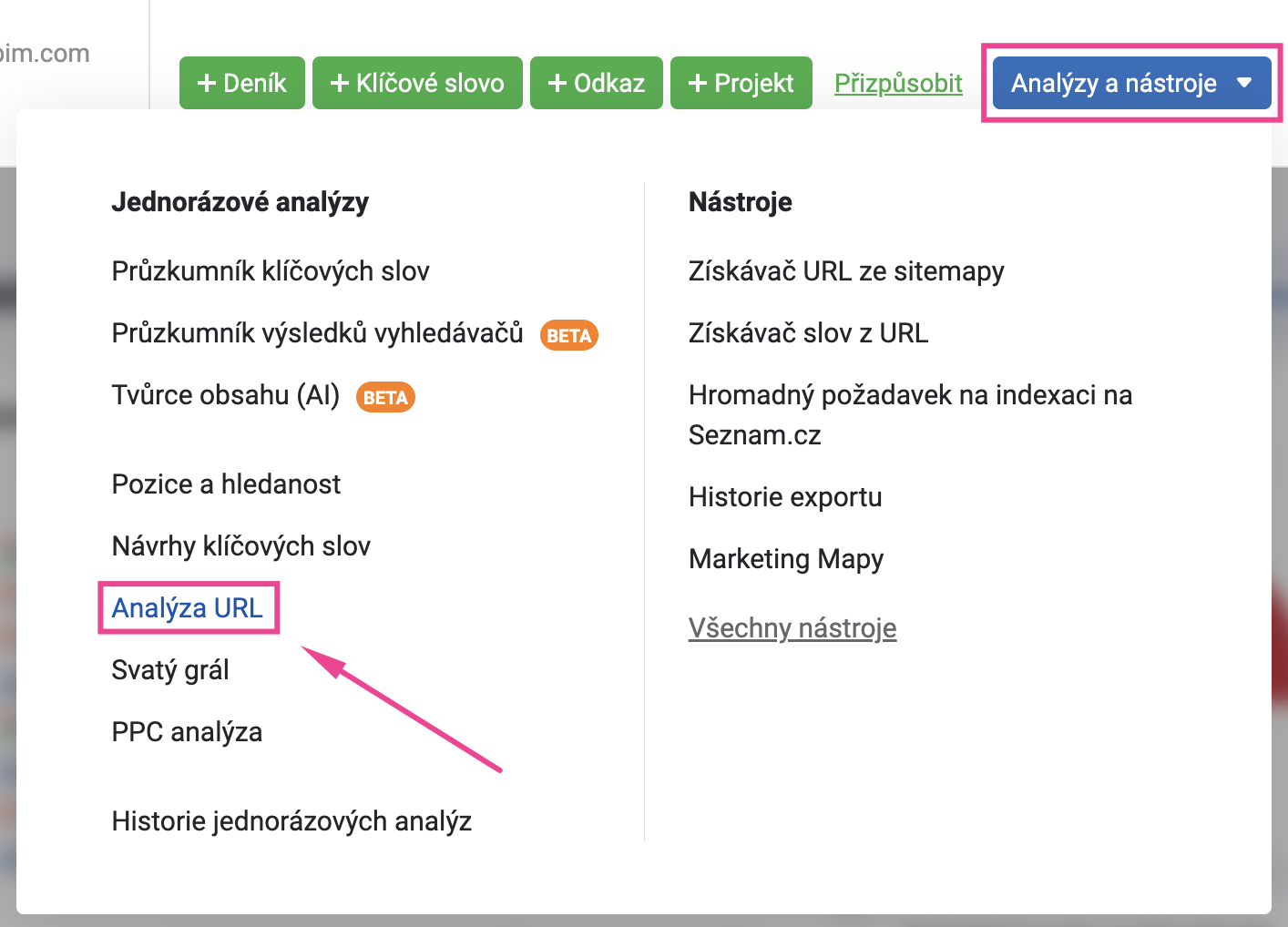
V případě, že potřebujete ověřit jen jednu nebo několik konkrétních URL, vložte příslušné adresy takto do schránky.
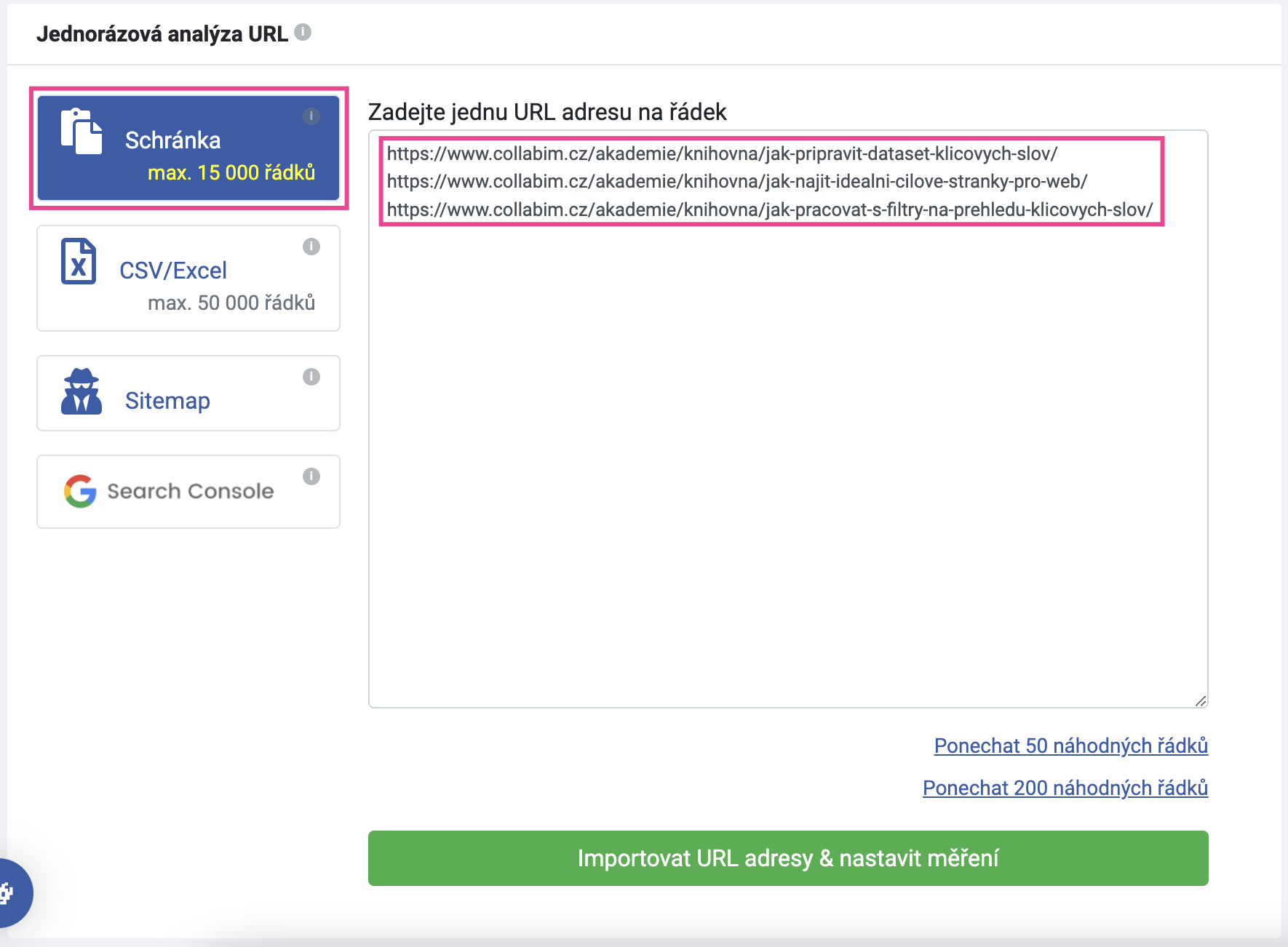
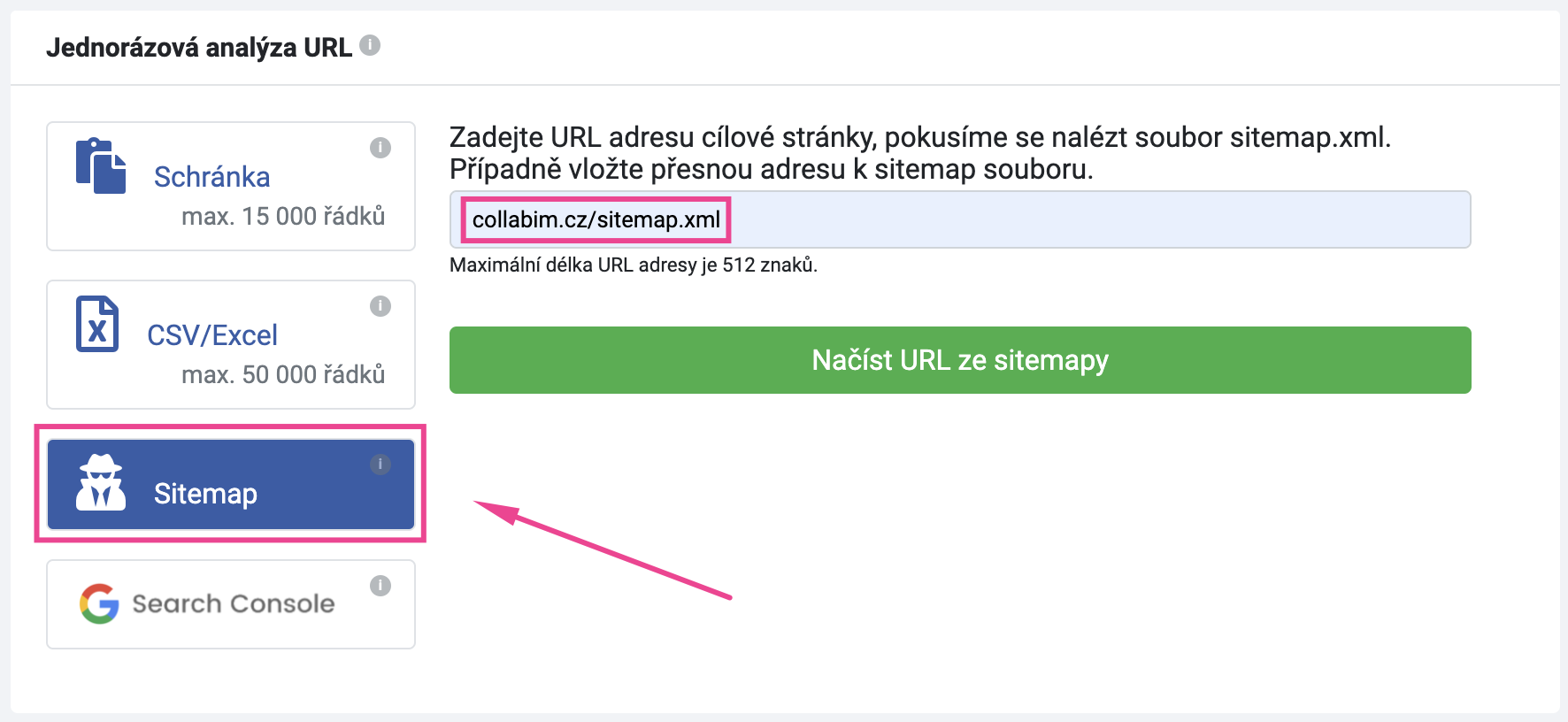
Nicméně pokud si přejete jednoduchým způsobem analyzovat celý web, ideální je načíst URL adresy přímo ze sitemapy webu.
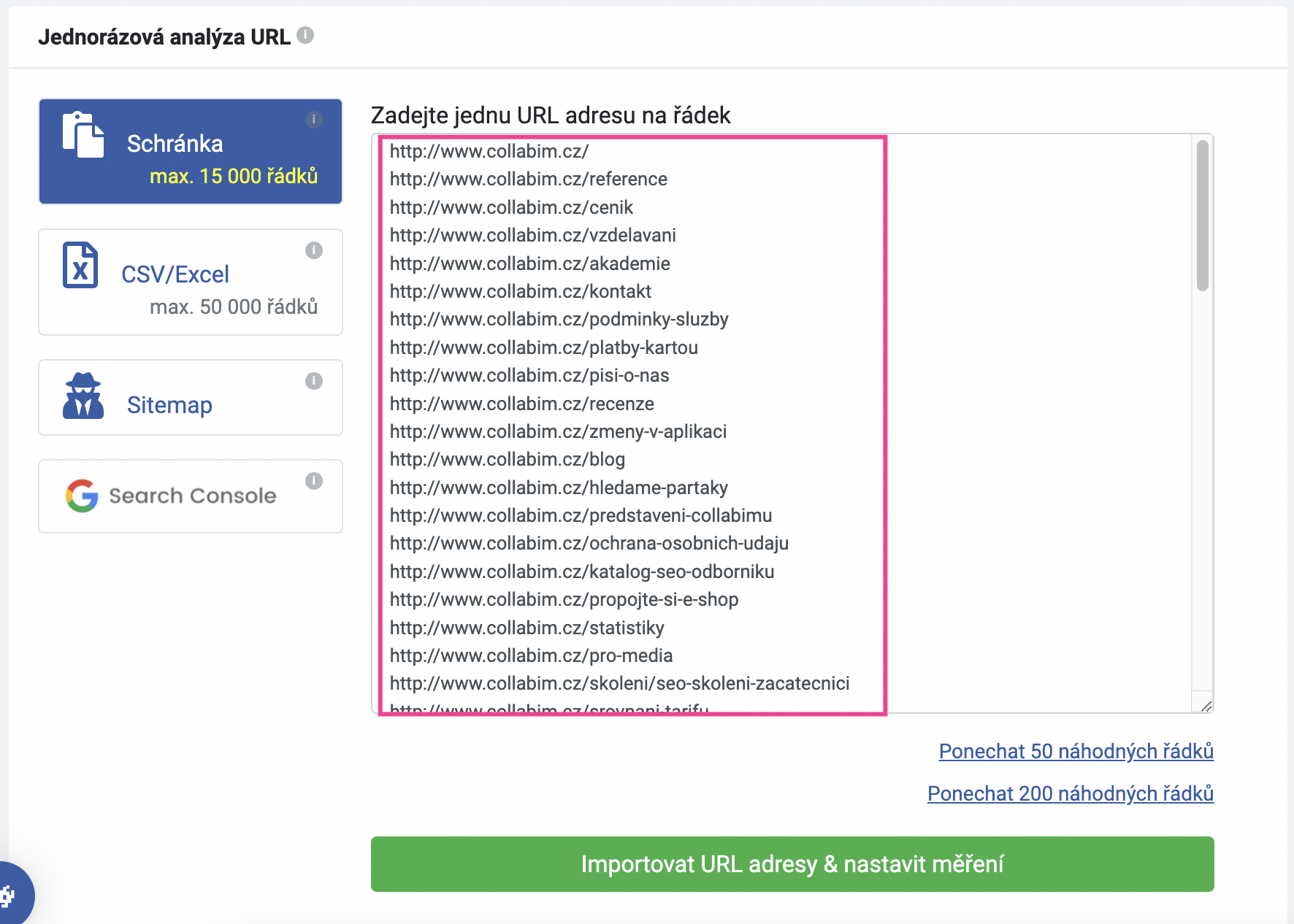
Jakmile potvrdíte načtení, do schránky se načtou jednotlivé URL adresy, které sitemapa obsahuje.
Neznáte adresu vaší sitemapy?
Pokud adresu vaší sitemapy neznáte, můžete zkusit zadat samotnou doménu – Collabim se pokusí najít sitemapu automaticky dle adres, které se pro sitemapu běžně používají.
Alternativně – adresu sitemapy najdete v souboru robots.txt na vašem webu.
Jak najít sitemapu v robots.txt?
Do vyhledávacího pole v prohlížeči zadejte adresu vašeho webu a za ni přidejte “/robots.txt“.
URL bude vypadat nějak takto:
![]()
Jakmile tuto URL vyhledáte, načte se vám obsah souboru robots.txt. Tento soubor primárně slouží pro správu přístupů robotům na vaše stránky, nicméně v něm najdete i adresu vaší sitemapy.

Jak vidíte na obrázku výše, náš soubor robots.txt obsahuje dokonce dvě sitemapy – jednu pro náš hlavní web a jednu pro naši akademii.
Stačí tedy zkopírovat URL sitemapy, ze které si přejete načíst stránky, a vložit ji do analýzy.
Příliš mnoho adres?
Pokud vaše sitemapa obsahuje příliš mnoho stránek a celkový počet přesahuje technické omezení analýzy, můžete to vyřešit tím, že URL adresy uložíte do tabulky a do analýzy naimportujete tabulku jako takovou. Import má totiž povolený větší limit – až 50 000 řádků.
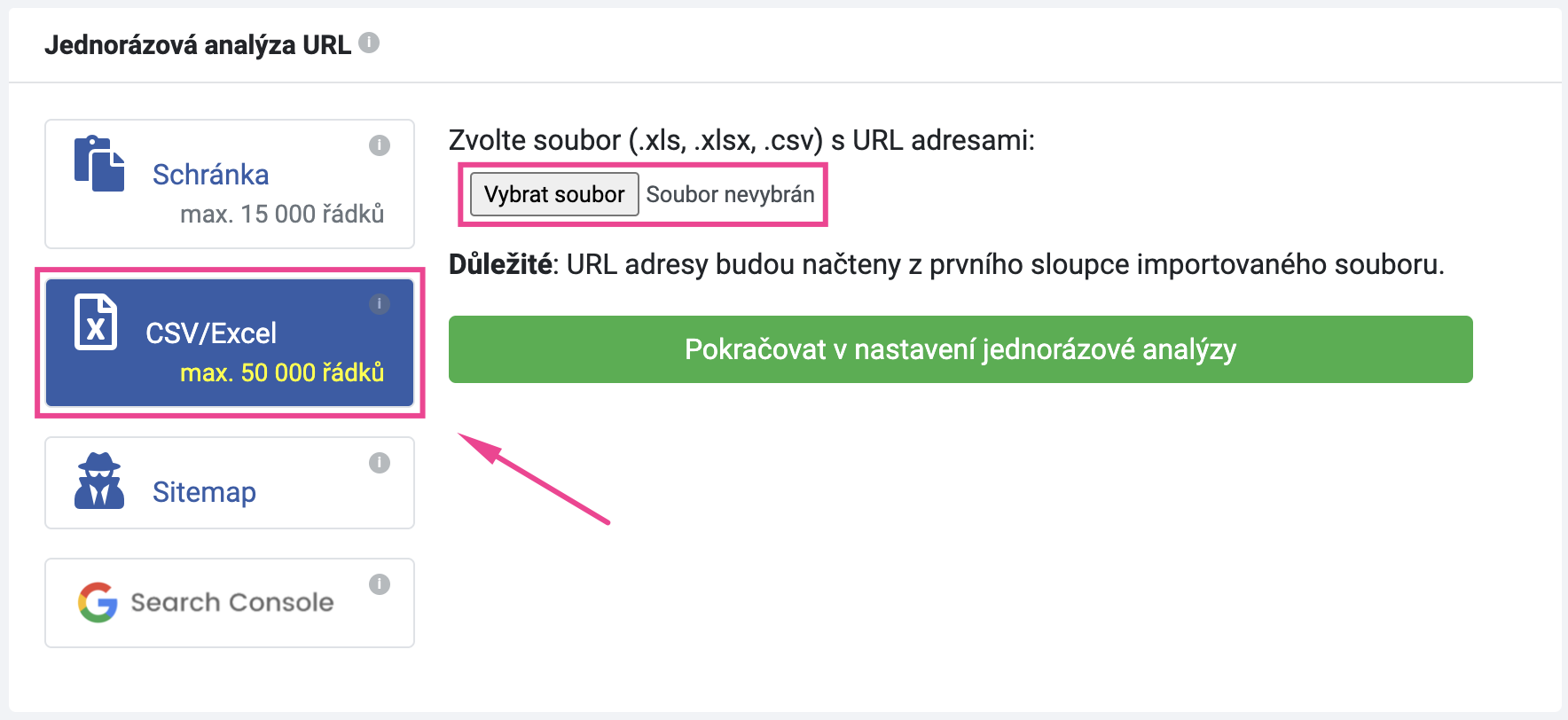
Abyste mohli provést import tabulky, bude třeba nejprve extrahovat všechny URL adresy ze sitemapy.
Jak extrahovat URL adresy ze sitemapy?
Pro získání všech URL adres můžete použít nástroj Získávač URL ze sitemap. Ten najdete opět v hlavičce aplikace v sekci Analýzy a nástroje.
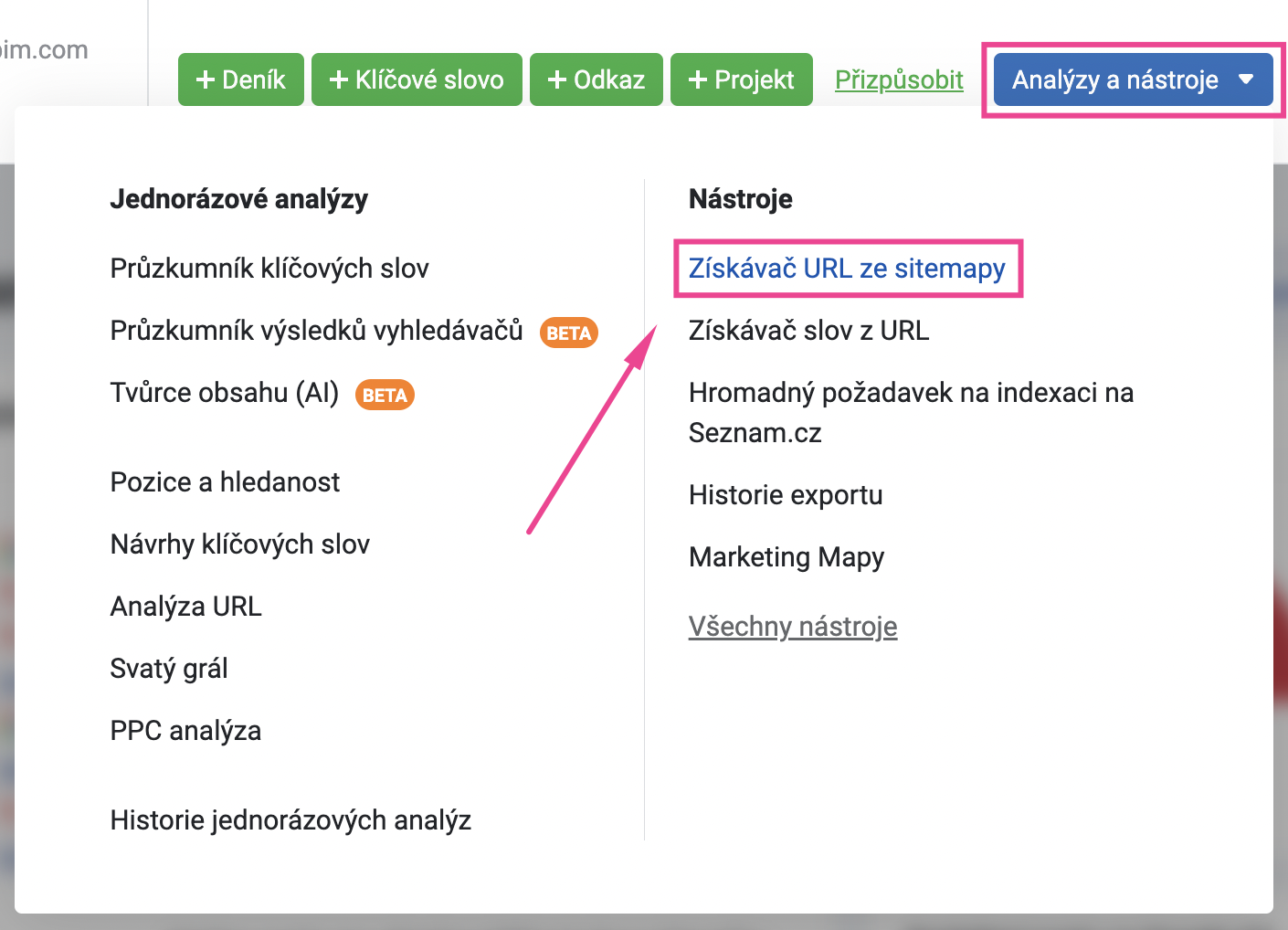
Do nástroje zadejte URL vaší sitemapy a klikněte na tlačítko “Exportovat do .xls“.
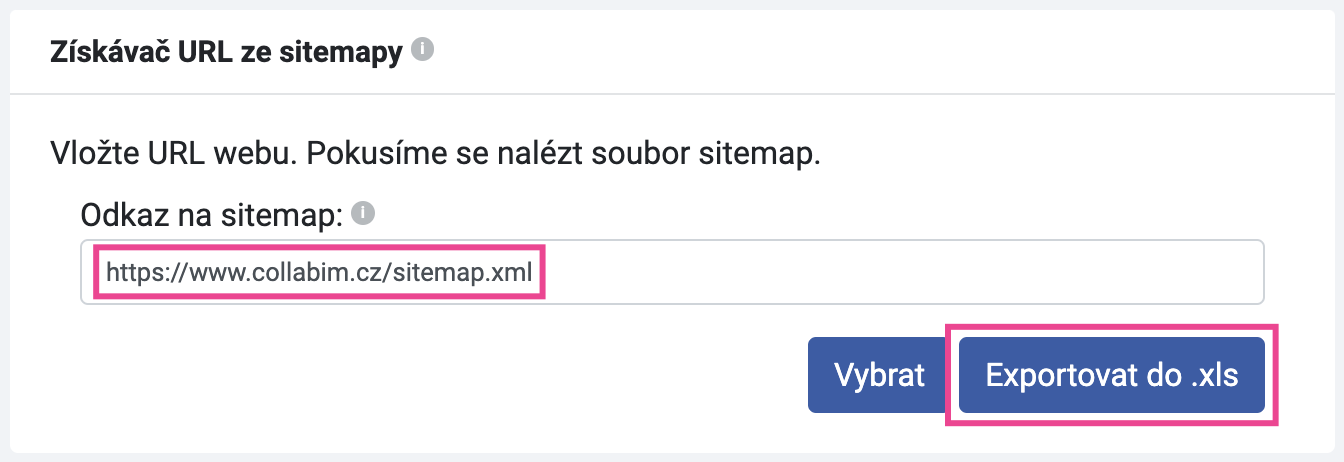
Obsah sitemapy se exportuje do tabulky, ve které pak najdete seznam všech URL adres.
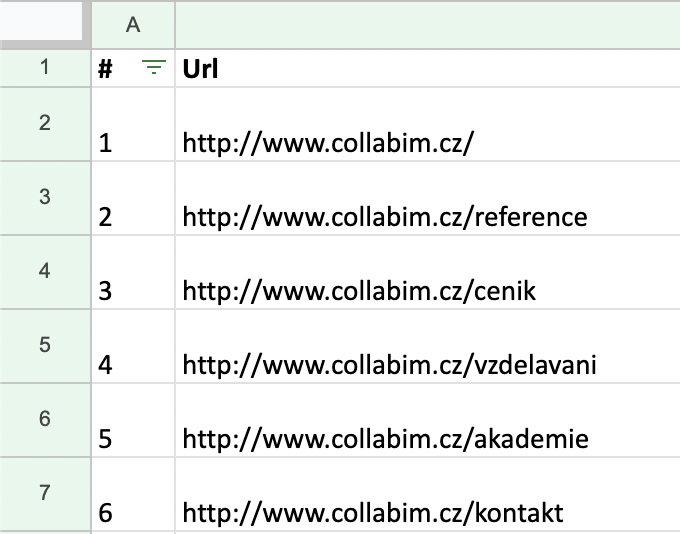
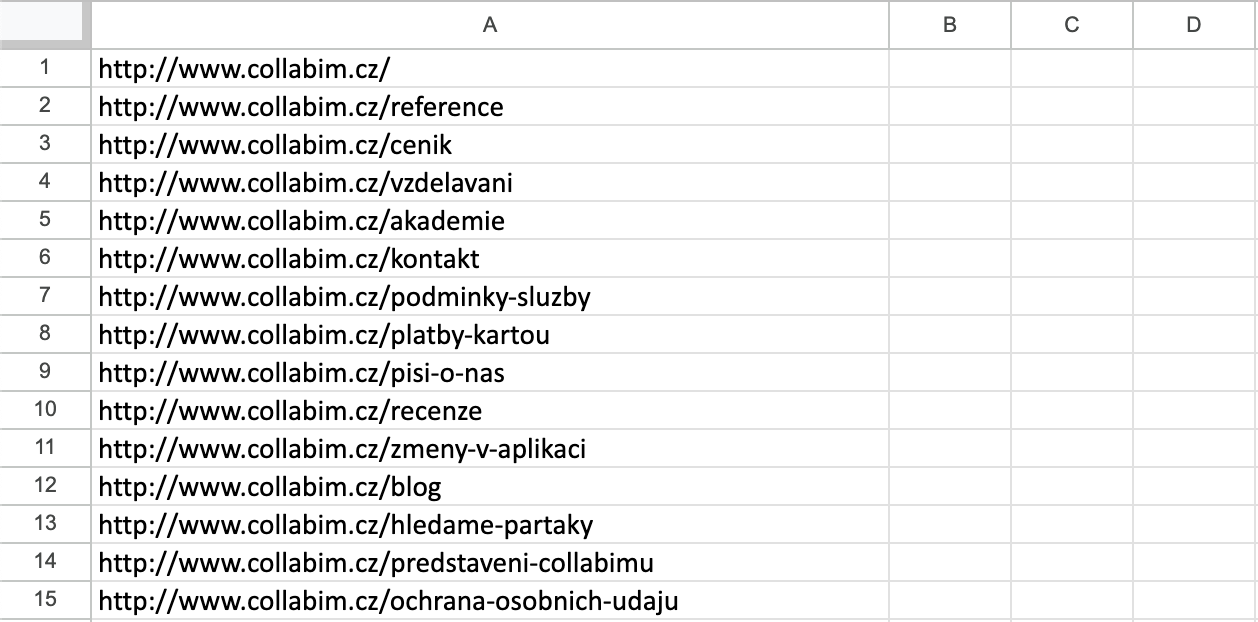
Nyní je třeba tabulku drobně vyčistit. Pro správný import je zapotřebí, aby tabulka obsahovala pouze URL adresy.
- Je nutné, aby se všechny URL adresy nacházely ve sloupečku A
- Odstraňte první řádek s nadpisy sloupců
- Zrušte filtry
- Smažte zbývající sloupečky s dalšími údaji
Po úpravách by tabulka měla vypadat podobně jako tato:
Uložte upravenou tabulku a naimportujte ji do analýzy URL.
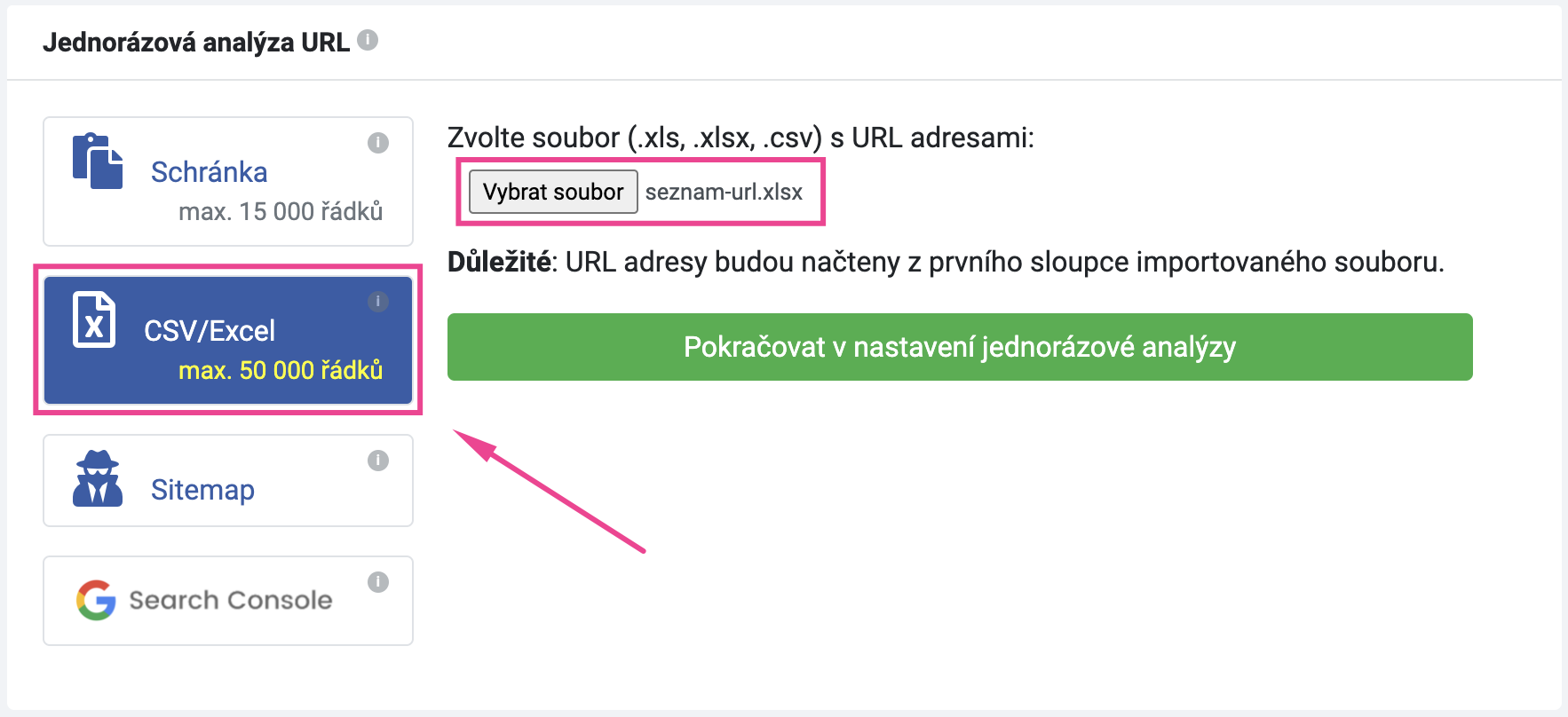
Pokračujte k nastavení analýzy. Data z tabulky se obratem načtou a poté již můžete nastavit specifikaci analýzy.
Obsahuje tabulka více než 50 000 řádků?
V takovém případě bude třeba tabulku rozdělit na více souborů a analýzu spustit vícekrát.
- Připravte dvě nebo více tabulek tak, aby každá obsahovala max. 50 000 řádků (pozor na prázdné řádky mezi URL adresami)
- Spusťte analýzu pro každý soubor zvlášť
Jak na vnořené sitemapy?
Při extrahování URL adres jste možná zjistili, že vaše sitemapa obsahuje další sitemapy. Pro získání URL adres z vnořených sitemap můžete aplikovat klasický postup extrahování, jen je třeba jej opakovat. Tzn.:
- Spusťte Získávač URL ze sitemap
- Vložte URL hlavní sitemapy
- Tím se rozbalí obsah s vnořenými sitemapami
- Adresu vnořené sitemapy vložte:
- buďto do Analýzy URL – pro načtení URL ze sitemapy a následné spuštění analýzy
- anebo opět do Získávače klíčových slov – pro extrahování jednotivých URL adres
- To můžete využít, pokud sitemapa obsahuje větší počet stránek, které potřebujete rozdělit do více tabulek
- Tabulky pak můžete naimportovat do analýzy
Nastavení analýzy
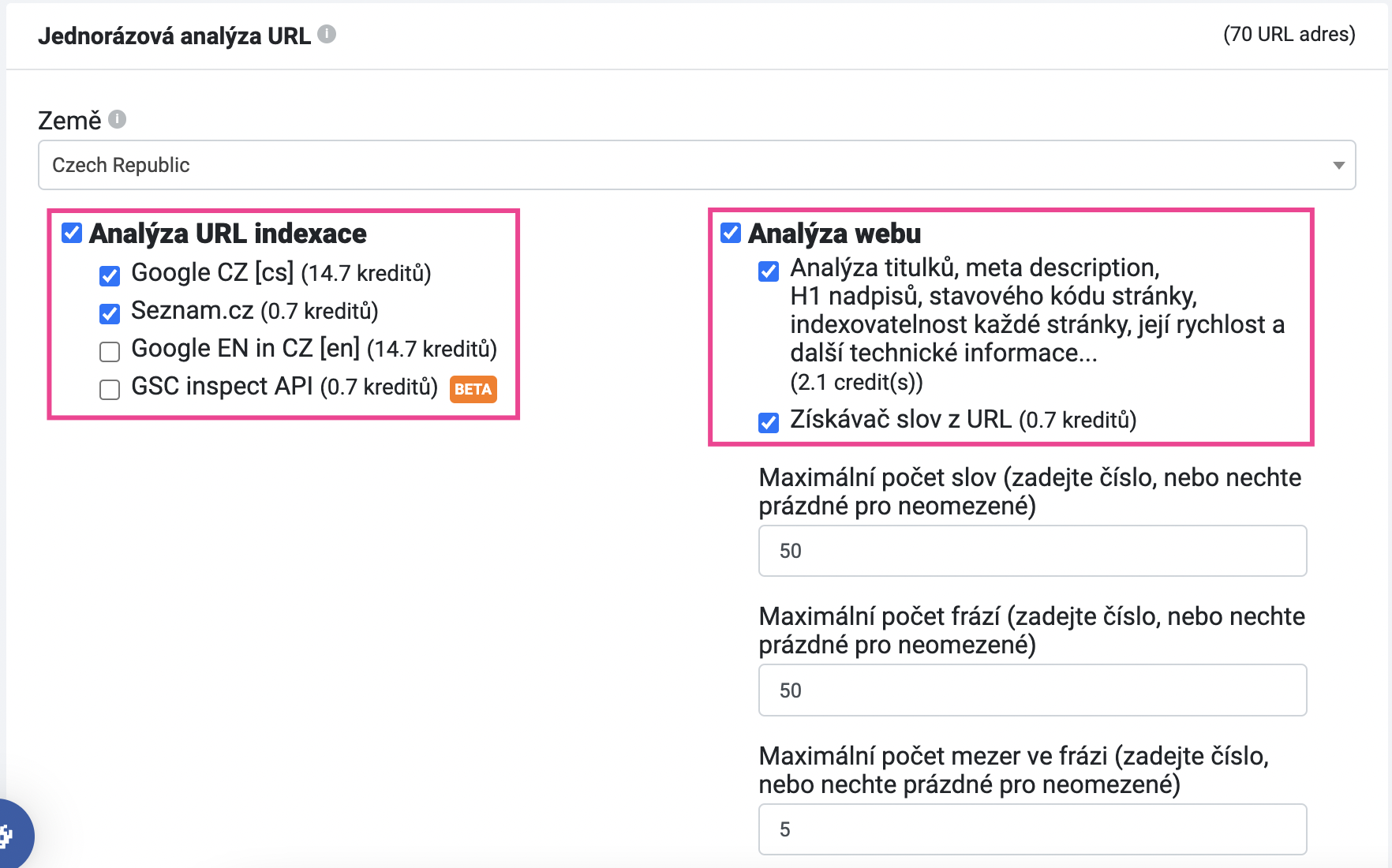
V dalším kroku můžete nastavit, co přesně si přejete analyzovat. Ověření, zda jsou URL indexované je základ, doporučujeme však nastavit i analýzu webu.
Analýza webu především ověří:
- zda stránky nepoužívají stejné titulky, popisky nebo nadpisy
- rychlost načtení HTML
- a další
Případně můžete nastavit i nástroj Získávač slov z URL, který zkontroluje, jaká klíčová slova se nachází v jednotlivých elementech stránky (např. v titulcích stránek, descriptionech, body, titulcích odkazů apod.). Pro základní technický přehled to však není úplně nutné.
Výsledky analýzy
Jakmile se analýza dokončí, můžete přejít na grafický náhled výsledků. V horní části najdete jednotlivé záložky – podle toho, jak jste analýzu nastavili.
- Indexace – informace, zda jsou stránky indexované
- Analýza webu – technické údaje
- Získávač slov z URL – klíčová slova nalezená v elementech stránek
- Možné problémy s indexovatelností – kontrola metadat a souboru robots.txt z hlediska indexovatelnosti
Záložka Indexace
Nejprve zkontrolujte, zda jsou stránky zaindexované v pořádku. V našem příkladu na grafech níže vidíme, že 68 URL adres z celkových 70 není indexováno na Googlu. Objemná červená výplň grafu si určitě zaslouží pozornost.
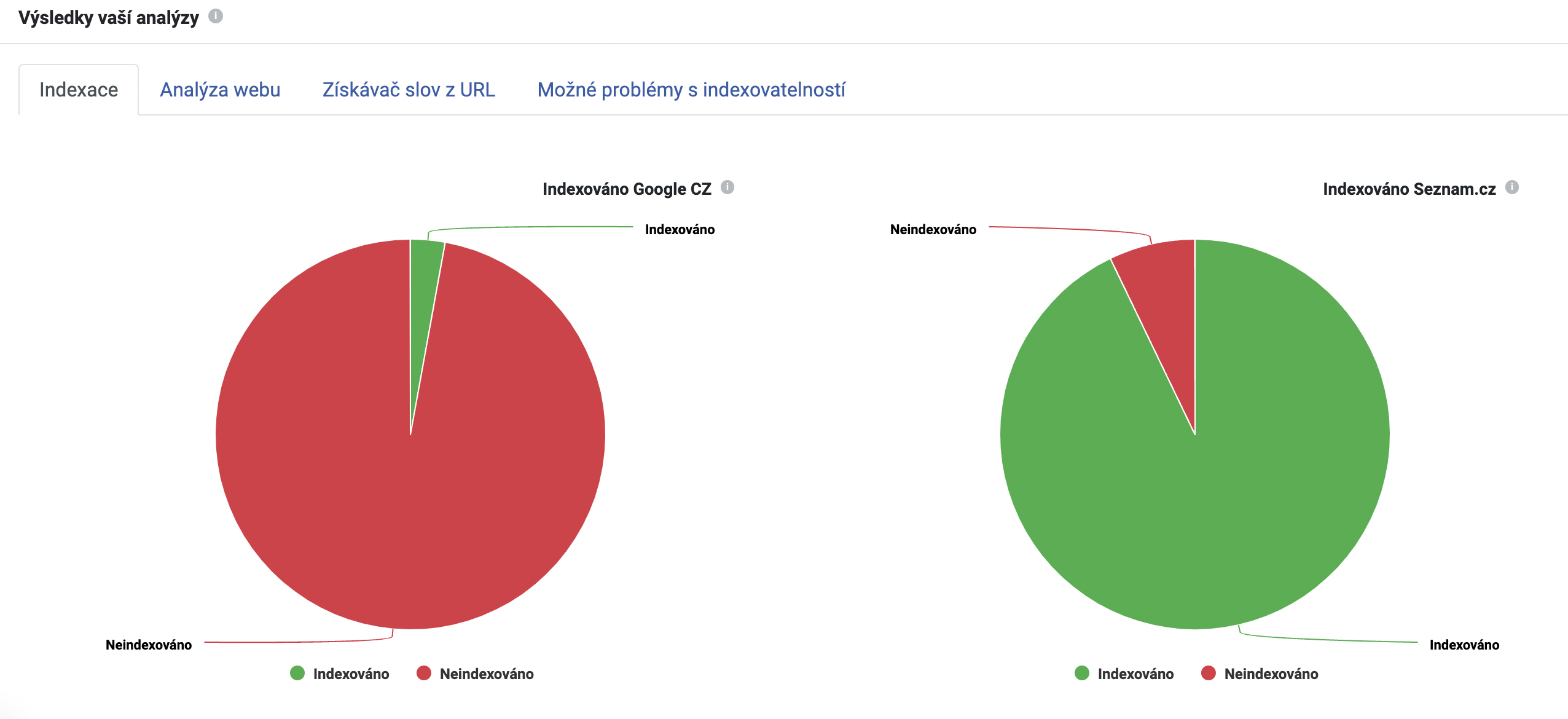
V tabulce pod grafy případně najdeme přehled jednotlivých URL adres a jejich stav indexace.
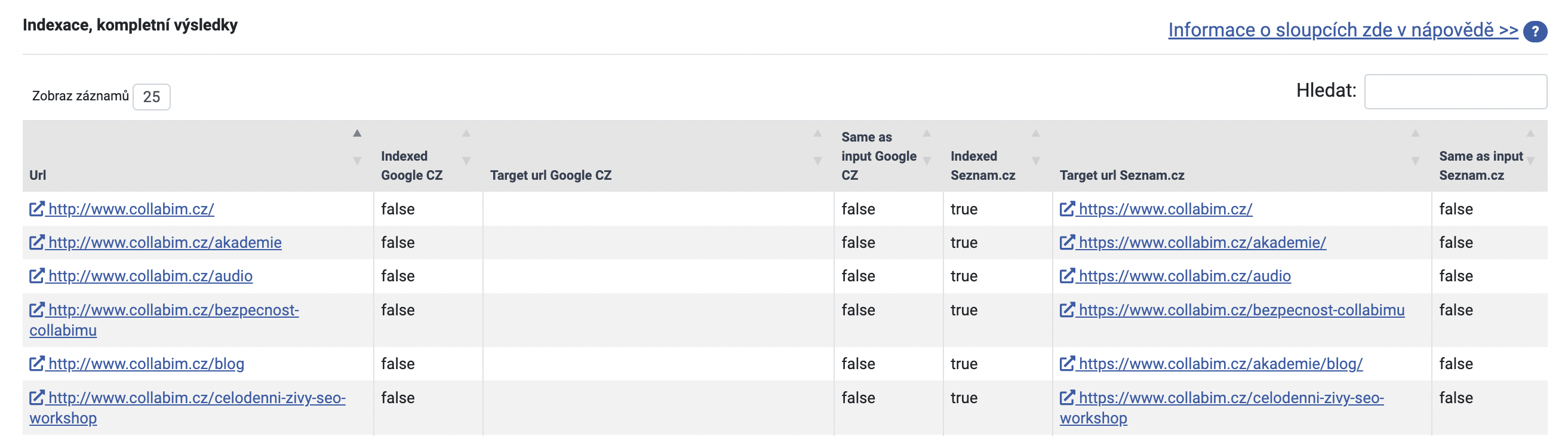
Nejprve ověřte, jestli indexace stránek není zakázána záměrně. Přejděte tedy na záložku Možné problémy s indexovatelností a zkontrolujte tabulku.
Seřaďte si sloupeček Indexováno dle hodnoty false, abyste viděli neindexované stránky. Nyní se zaměřte na sloupečky Meta tag robots a Robots txt.
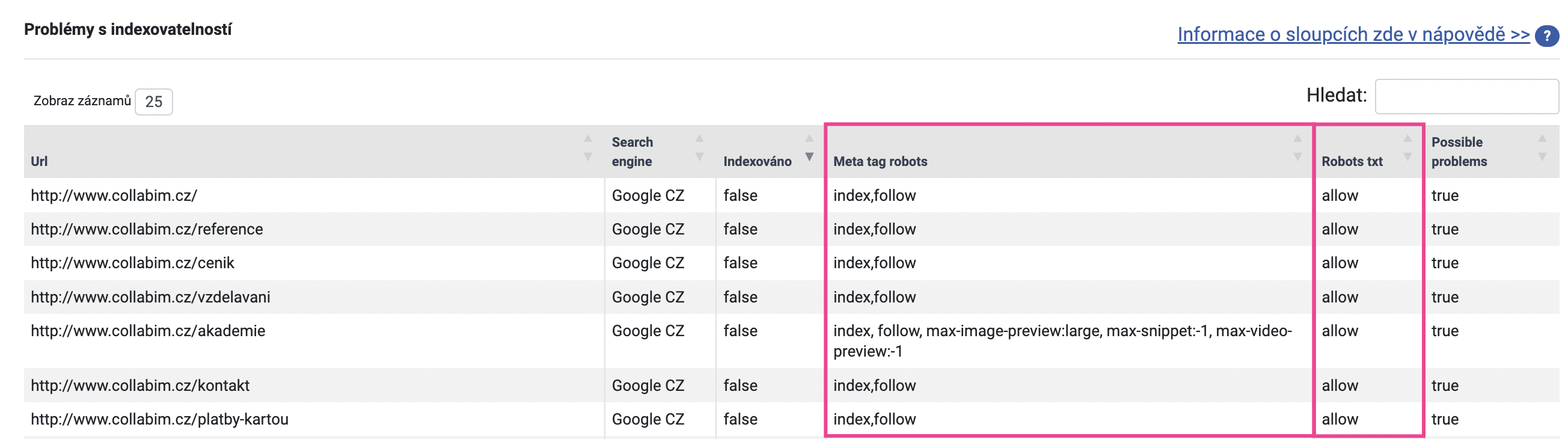
Sloupeček Meta tag robots
Ve sloupečku Meta tag robots ověřte, zda stránky neobsahují značku “noindex“. Tato značka totiž vyjadřuje, že stránka nemá být indexována. Toto se obvykle používá u stránek, u nichž si nepřejete, aby byly zobrazeny ve vyhledávání – často se to týká např. děkovacích stránek apod.
Pokud by nějaká stránka obsahovala značku “noindex”, zkontrolujte, zda je to tak správně. Může to být záměr (např. u děkovací stránky), ale stejně tak se mohlo stát, že značka byla na stránku přidána omylem (např. při editaci).
V našem případě žádná ze stránek značku “noindex” nemá, tudíž v tomto problém nebude. Přejděte na sloupeček Robots txt.
Sloupeček Robots txt
Robots.txt je soubor na webu, který obsahuje údaje o tom, zda stránky mají povolené přístupy pro roboty. V příslušném sloupečku zkontrolujte, zda jsou přístupy povolené (“allow” – povoleno).
Pokud byste nalezli hodnotu “disallow” – pak je přístup robotům zakázaný. To může být příčina problému – pokud by stránka zakazovala přístup Google robotovi, nemohl by stránku projít a zaindexovat.
Naše analýza hlásí, že přístupy robotům jsou u všech URL povolené. Všechny stránky tedy mají základní předpoklady pro to, aby mohly být indexované. Příčina neindexování tedy bude mimo meta tagy a přístupy pro roboty.
Prověření indexace
Vraťte se na záložku Indexace. Podíváte-li se pozorně na URL adresy, které jsme vložili jako vstupní data do analýzy, všimněte si, že používají ještě nezabezpečený http protokol.
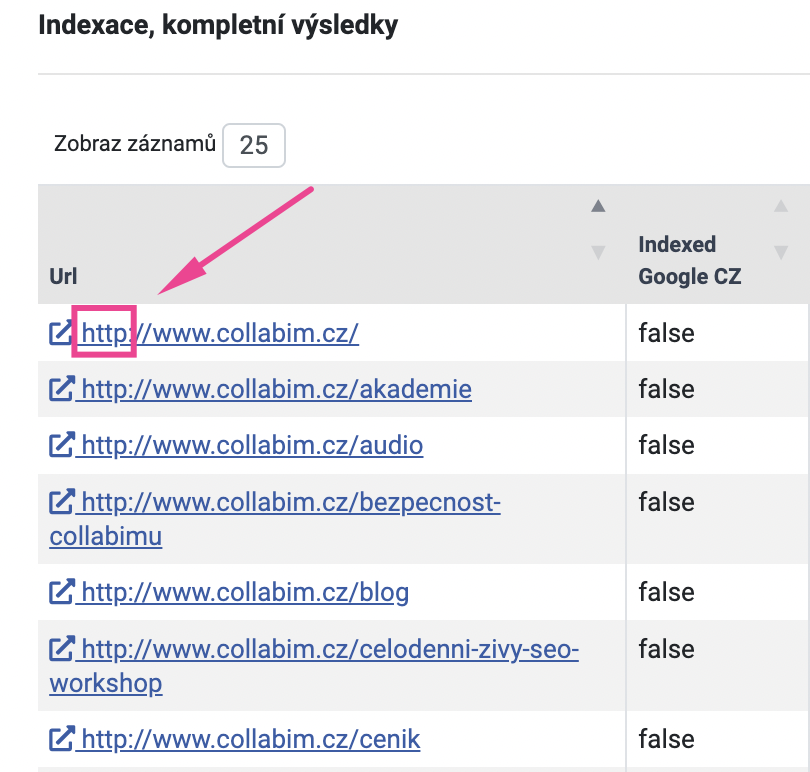
Pokud se prokliknete na některou z URL, zjistíte, že se zobrazí stránka se zabezpečeným protokolem https.

Vypadá to tedy, že stránka používá nějakou formu přesměrování – z http na https.
Ověříte-li přesměrování stránky přes nějaký externí nástroj (např. Redirect Checker), zjistíte, že stránka vrací stavový kód 301 – trvalé přesměrování.
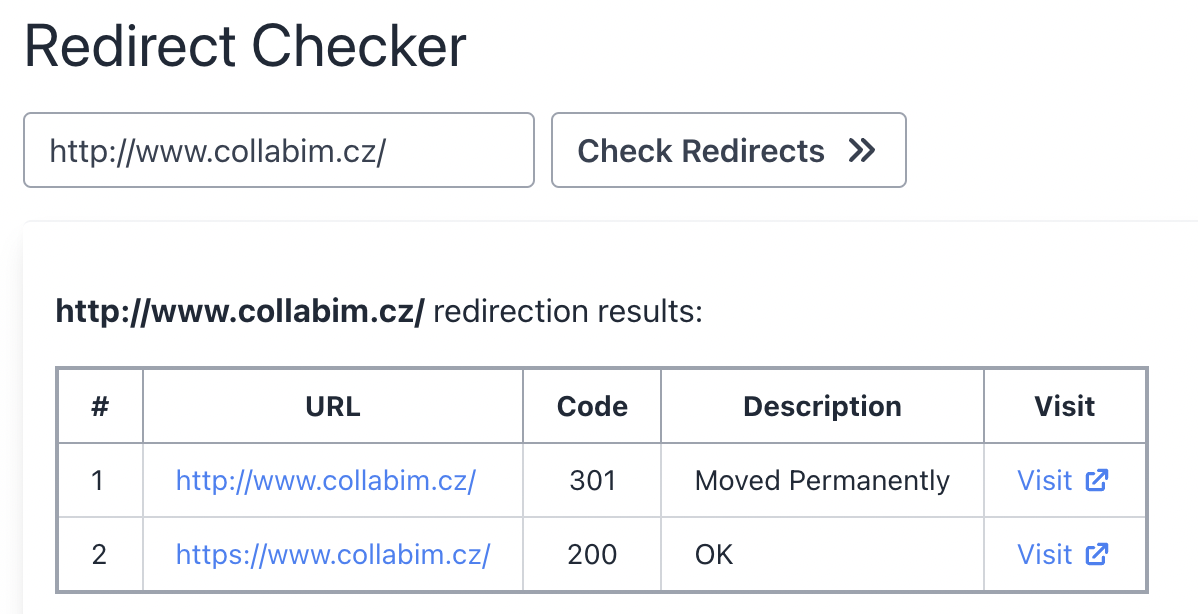
Tím jsme odhalili příčinu, proč stránky v naší analýze nejsou indexované. Naše sitemapa totiž obsahuje originální URL adresy s http protokolem, které jsou přesměrovány na https varianty.
Ověření
Zda jsou indexované https varianty můžete ověřit tak, že upravíte http protokoly v původním seznamu a spustíte novou analýzu. Úpravu můžete jednoduše provést např. v Tabulkách Google přes funkcí Najít a nahradit.
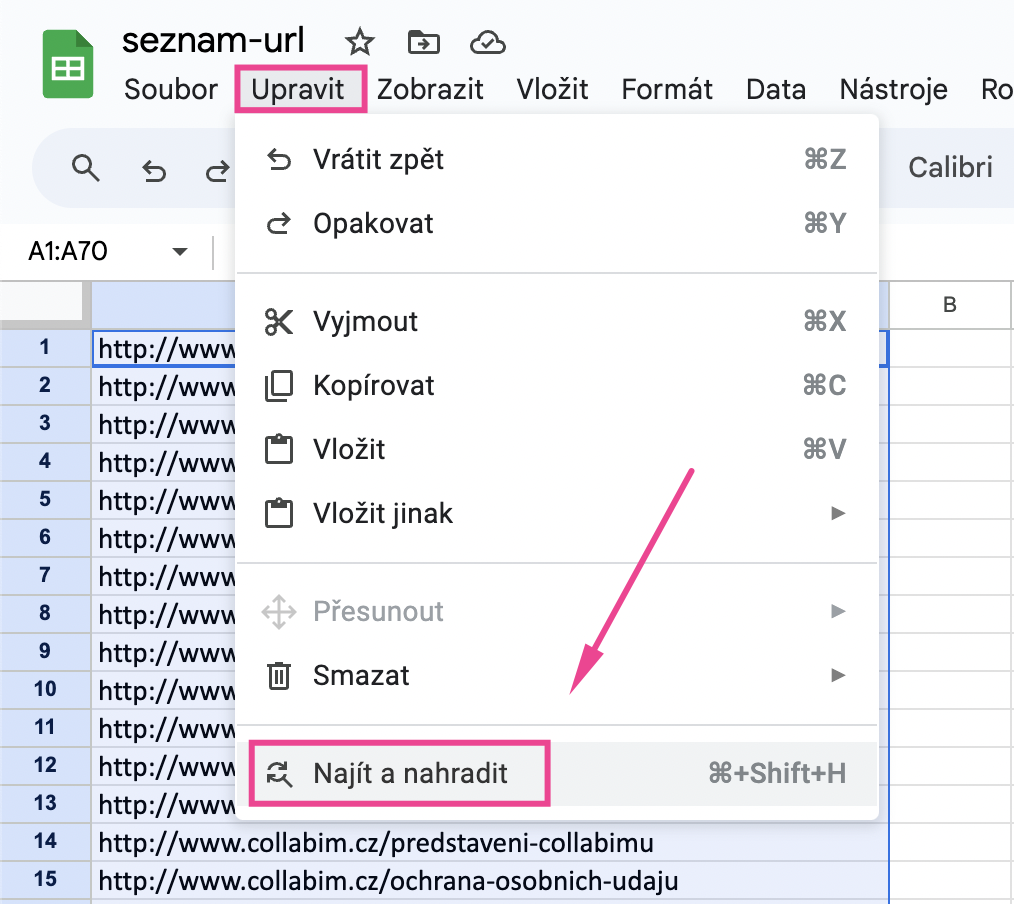
Pak jen nahradíte http za https.
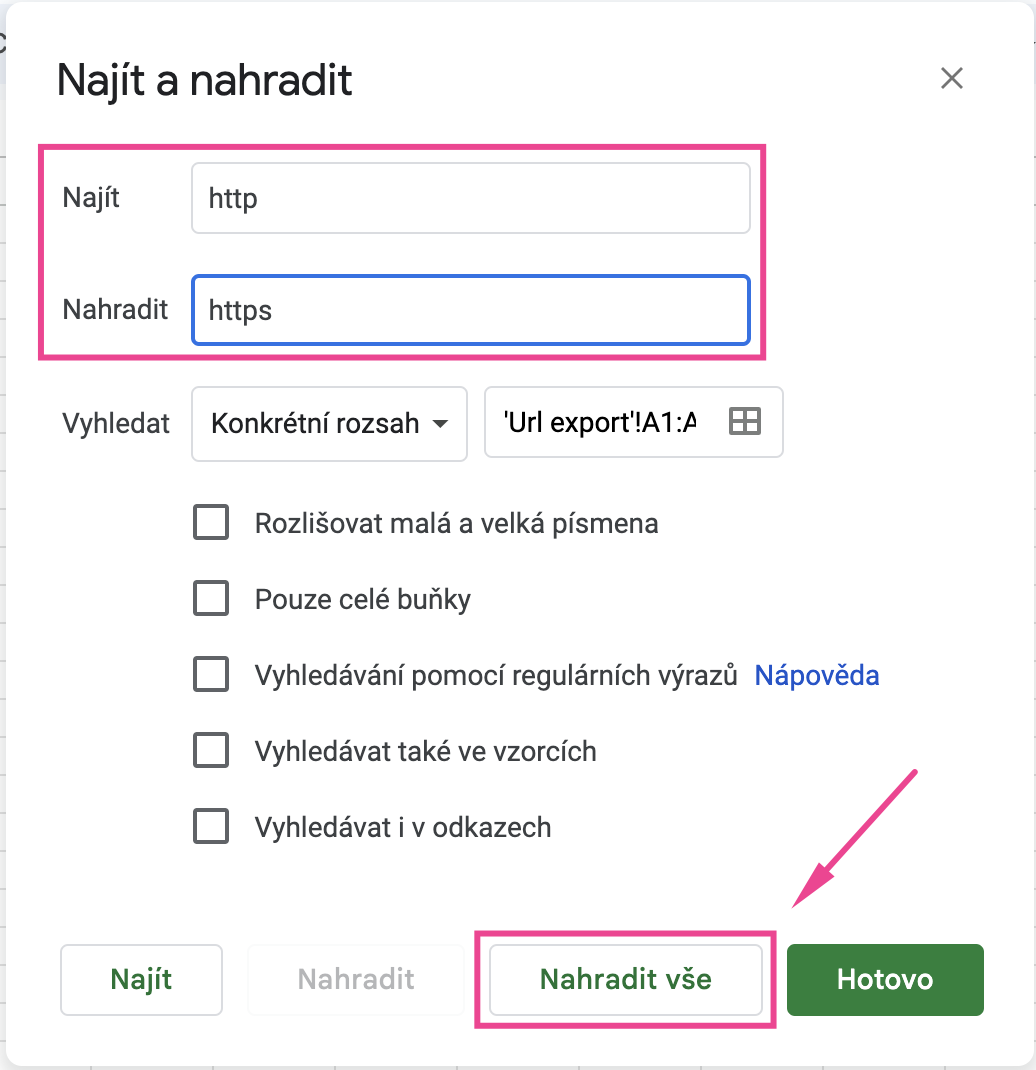
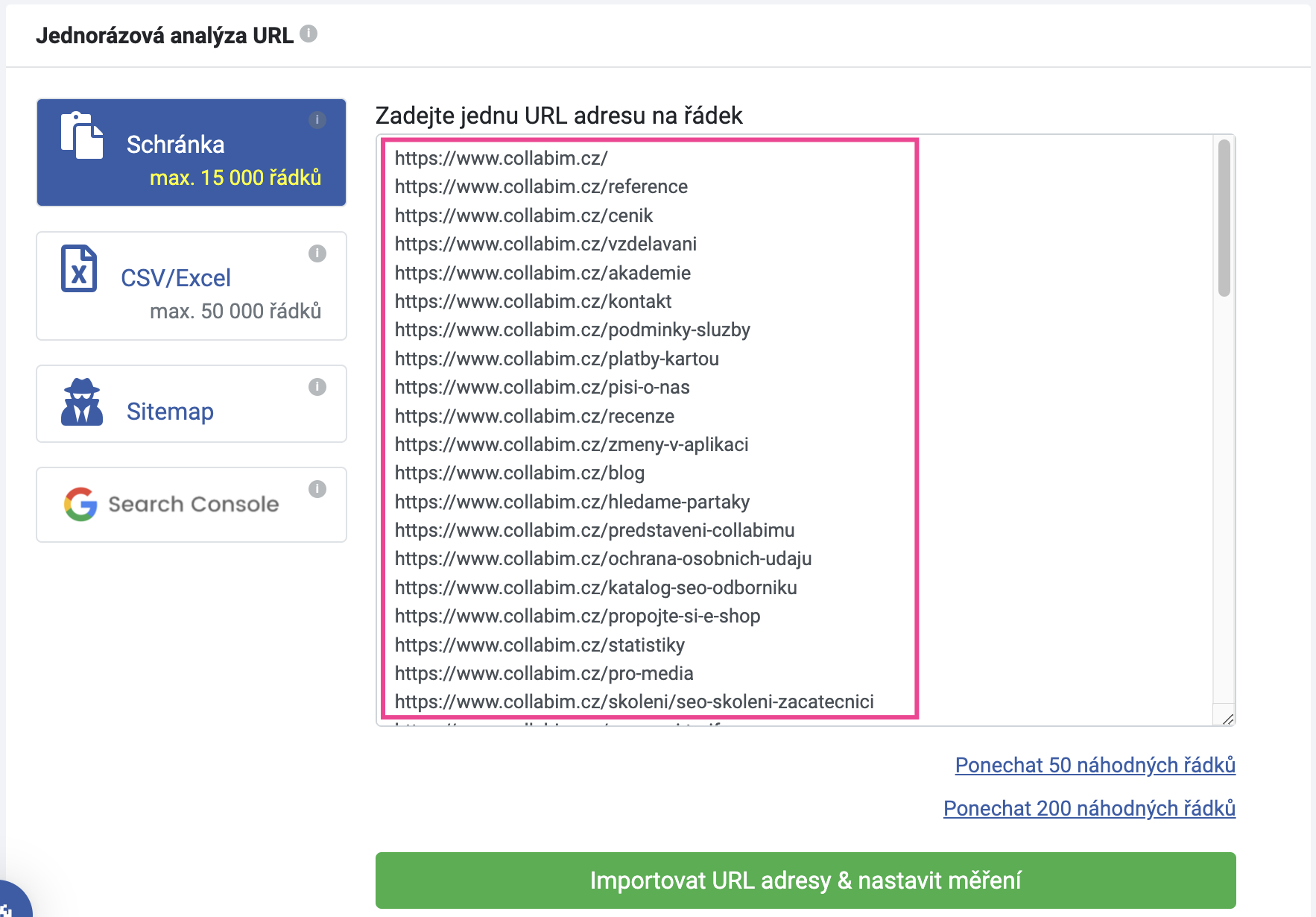
Do analýzy poté vložte URL s upraveným https protokolem.
Ve výsledcích nyní již vidíme, že https varianty jsou z velké části zaindexované.
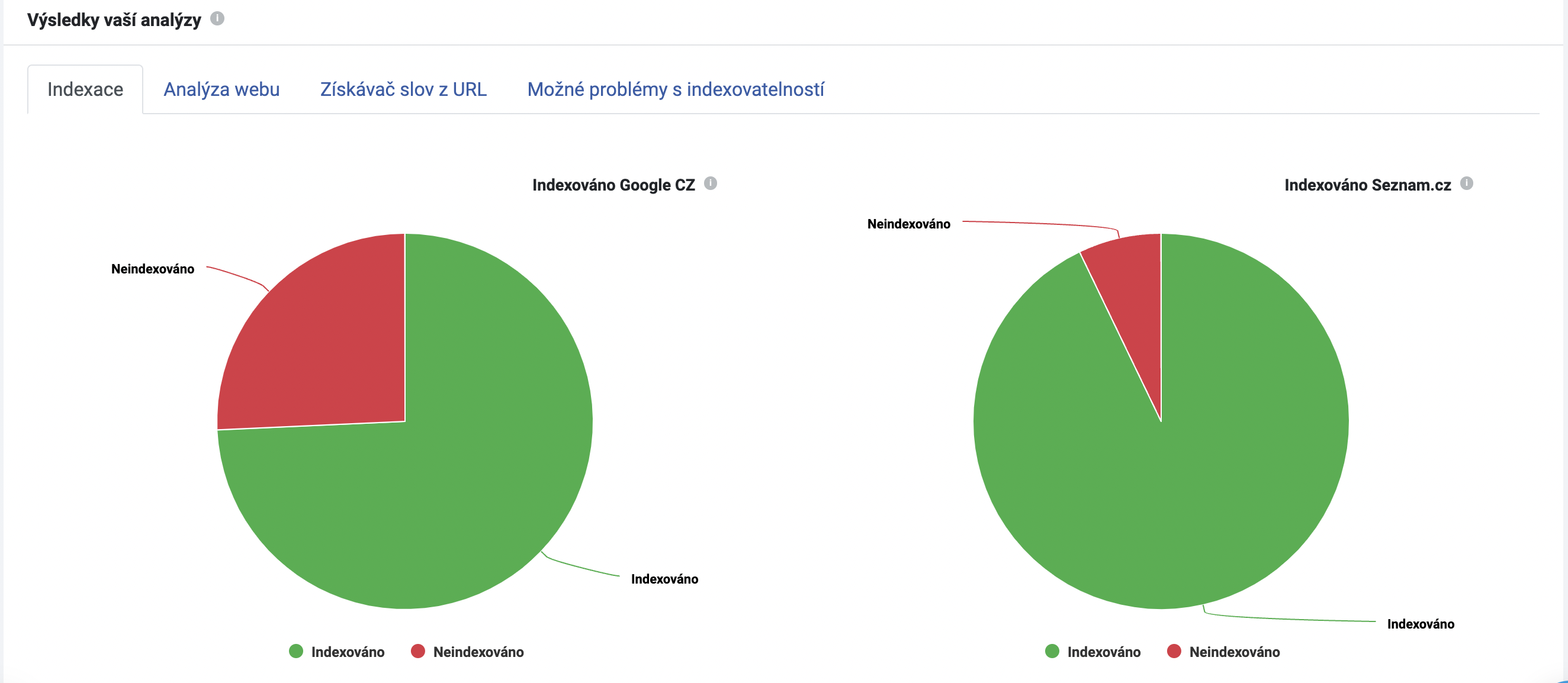
Podobně jako v předchozím případě – i nyní proveďte stejný postup prověření stránek, které nejsou indexované. V našem případě není zaindexováno celkem 17 adres ze 70.
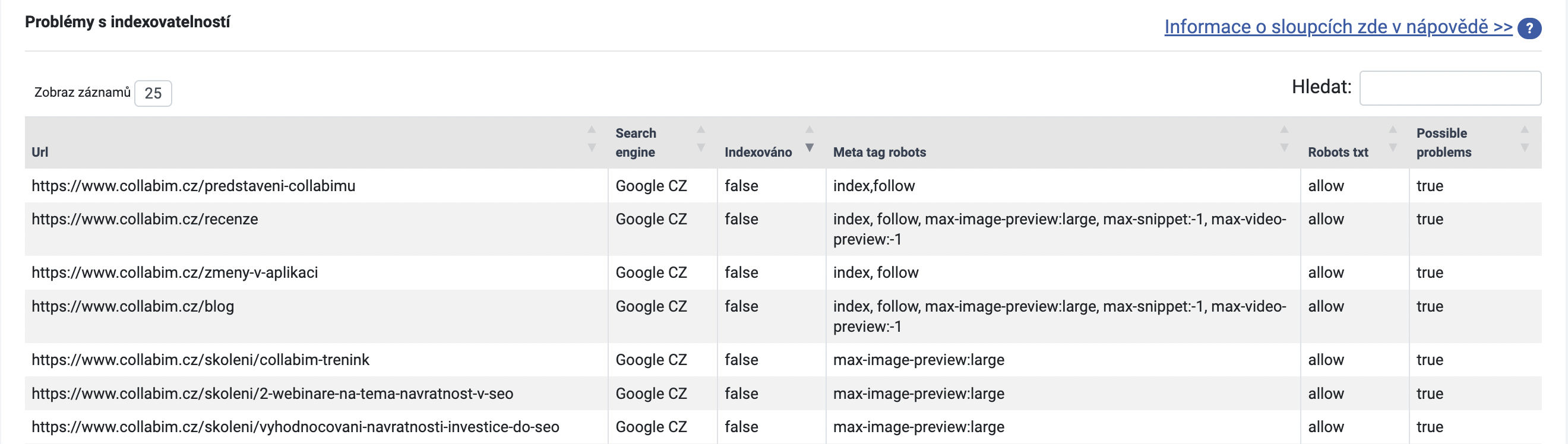
Opět jsme zkontrolovali URL adresy přes Redirect Checker – ve většině případů se jednalo o přesměrování na jiné adresy. Přesměrování jsme zkontrolovali a ověřili, zda jsou správná.
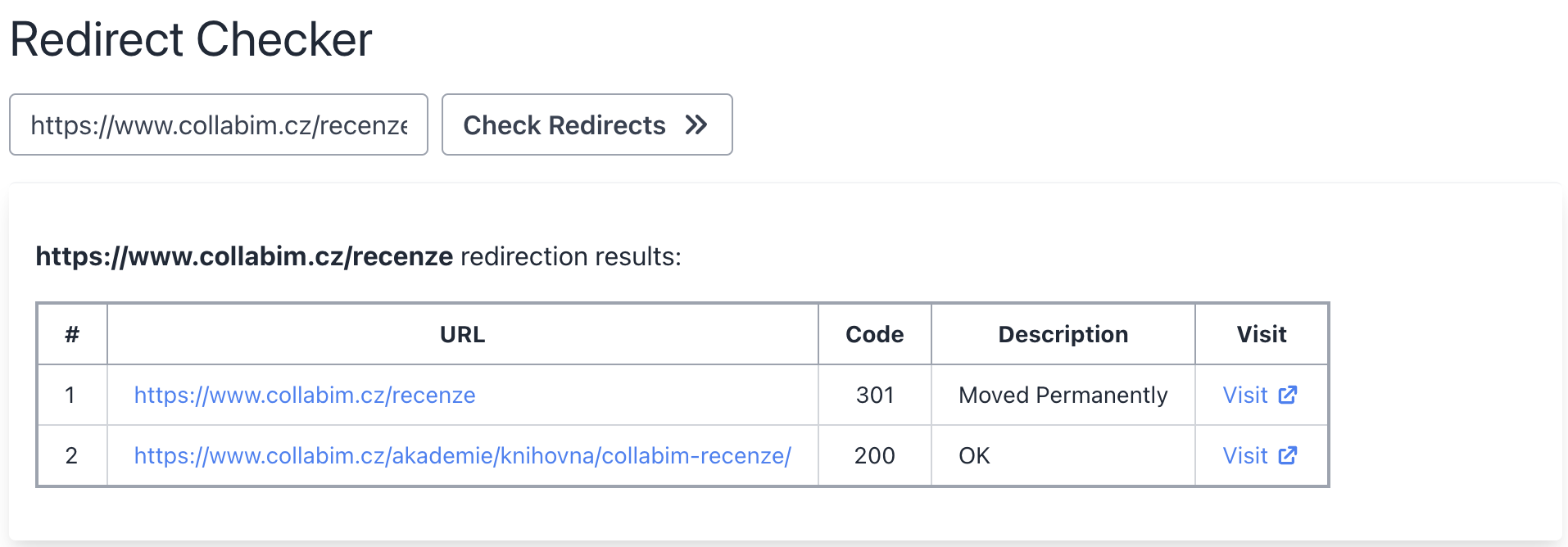
Výjimkou byla jedna novější URL adresa, která skutečně doposud nebyla indexována, konkrétně na Seznamu.
Jak zažádat o indexaci?
Každý vyhledávač má vlastní způsob pro požadavek o indexaci. Níže najdete postupy jednotlivé postupy:
Další možné problémy s indexovatelností
Pokud příčinou toho, že stránky nejsou indexované, nebylo přesměrování, značka “noindex” ani zakázané přístupy robotům, je vhodné zkontrolovat příslušné URL adresy ve vaší Google Search Consoli.
Ta totiž obvykle u stránek, které nejsou indexované, uvádí možné příčiny. V levém menu vyberte sekci Indexování a klikněte na podsekci Stránky.
Dostanete se na přehled, kde již najdete možné příčiny. Na ilustračním obrázku níže si můžete prohlédnout některé z příčin.
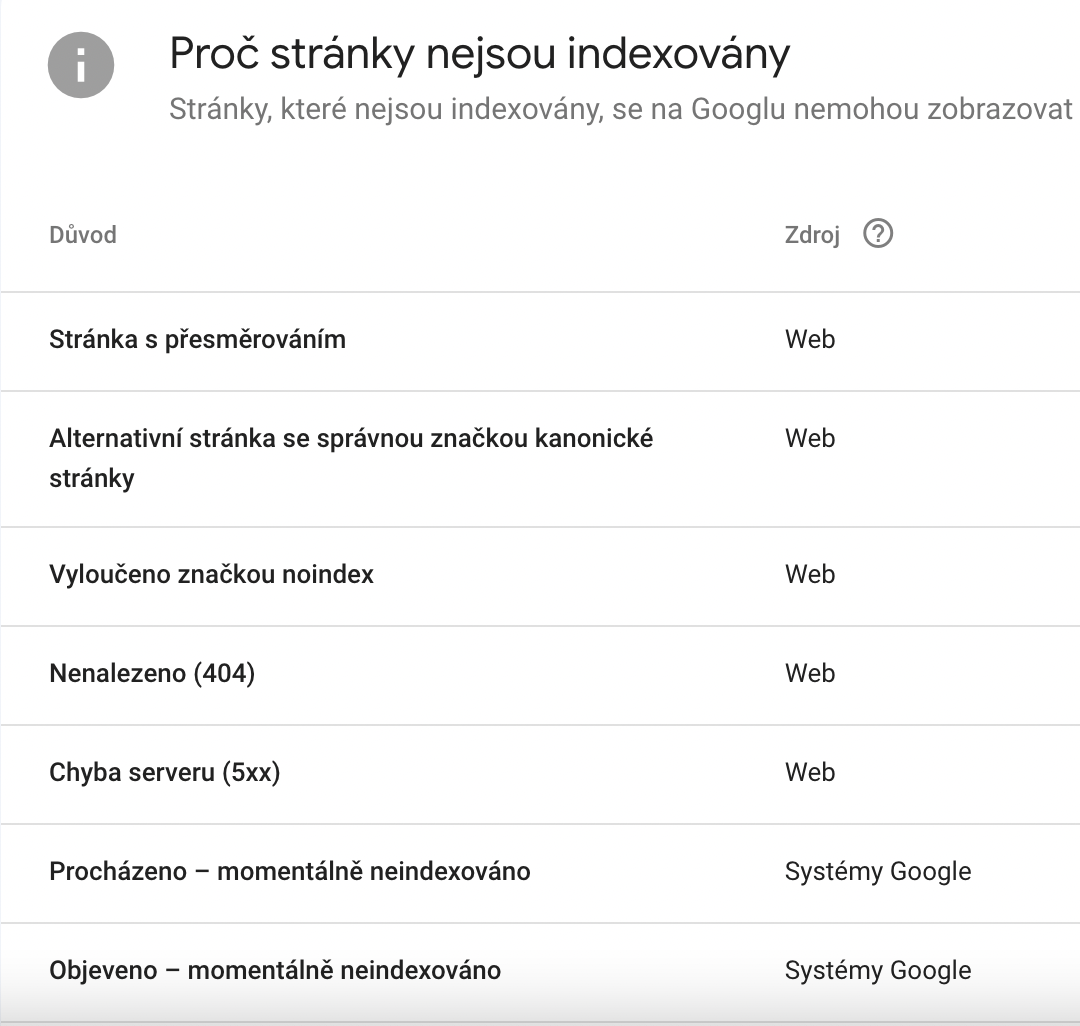
Časté příčiny neindexování:
- Stránky s přesměrováním (standardně nejsou zahrnuty v indexu)
- Stránky s duplicitním obsahem
- Kanonizace
- Neexistující stránky (404)
- Chyby serveru
- Objeveno – momentálně neindexováno / Procházeno – momentálně neindexováno
- Značka “noindex“
Pomineme-li technické důvody, příčinou neindexování tak může být i problém s obsahem na stránkách (duplicitní, nekvalitní, závadný, apod.).
Je tedy vhodné příslušné stránky zkontrolovat a případně zrevidovat.
Záložka Analýza webu
V technické analýze jste zkontrolovali indexaci stránek a nyní přejděte na záložku Analýza webu. Na této záložce můžete ověřit, zda stránky nepoužívají stejné titulky nebo popisky a další technické náležitosti.
Duplicitní elementy na stránkách
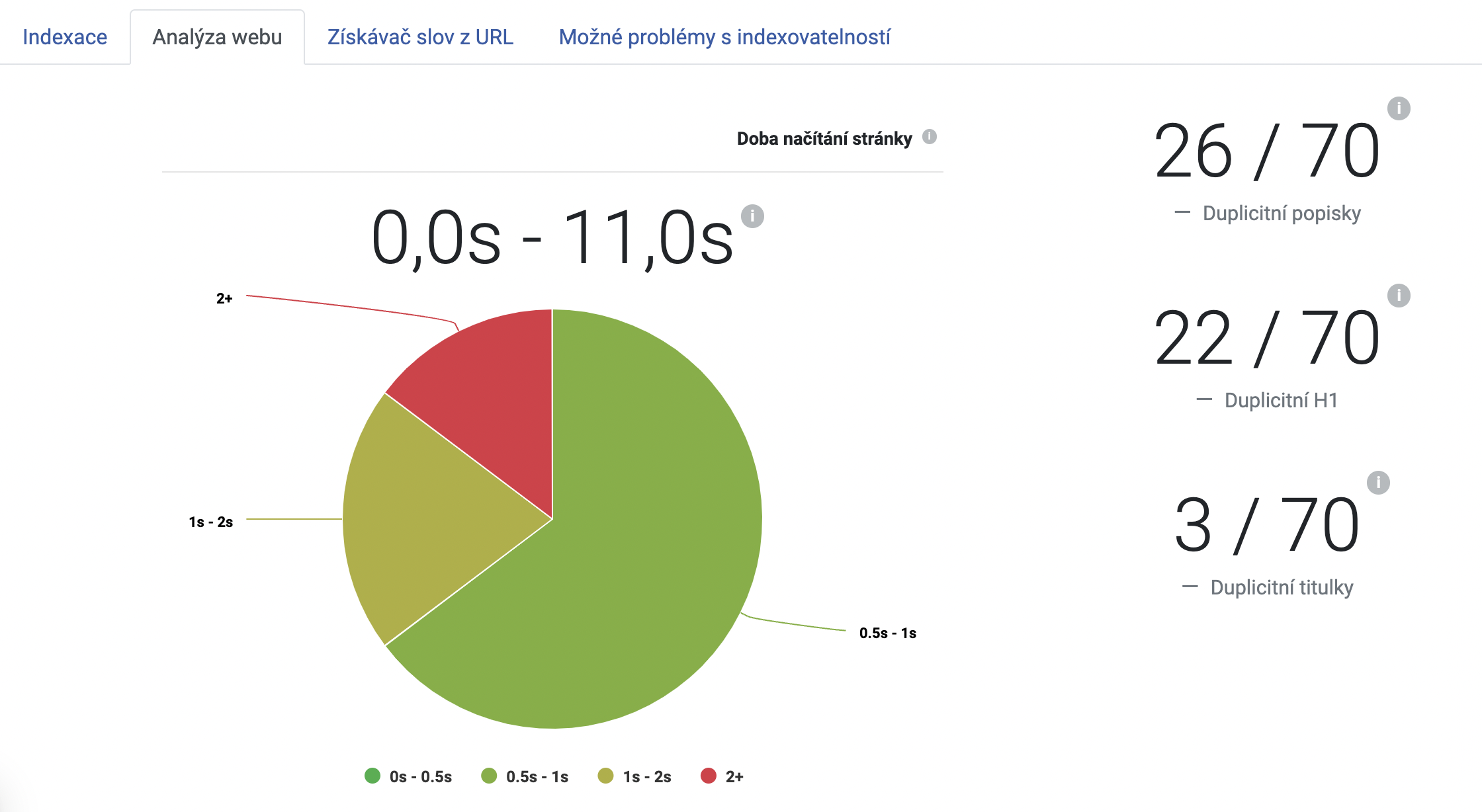
Na obrázku výše vidíte, že na našich stránkách máme celkem:
- 26 duplicitních popisků
- 22 duplicitních nadpisů H1
- 3 duplicitní titulky
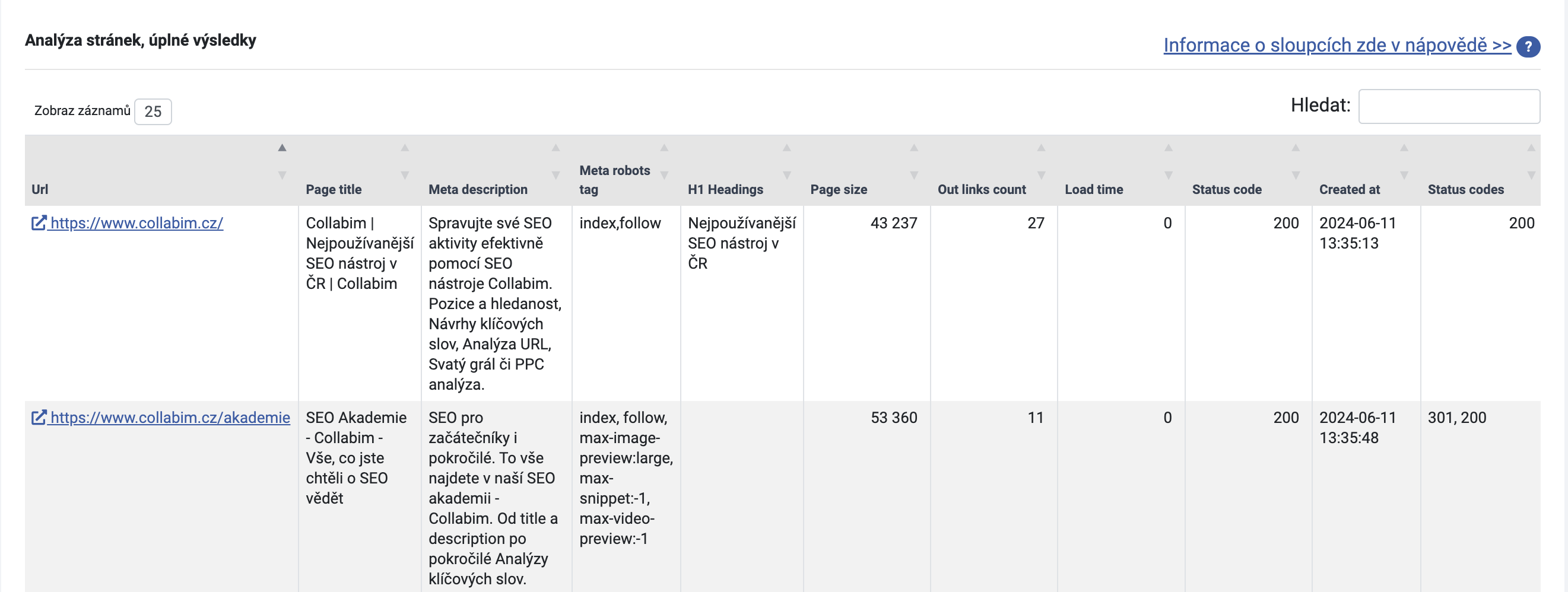
Podrobnosti najdete opět v tabulce pod grafy. Ačkoliv můžete výsledky filtrovat dle vyhledávacího pole napravo, pro lepší práci s tabulkou doporučujeme výsledky exportovat a se souborem pracovat přímo v Excelu nebo Tabulkách Google.
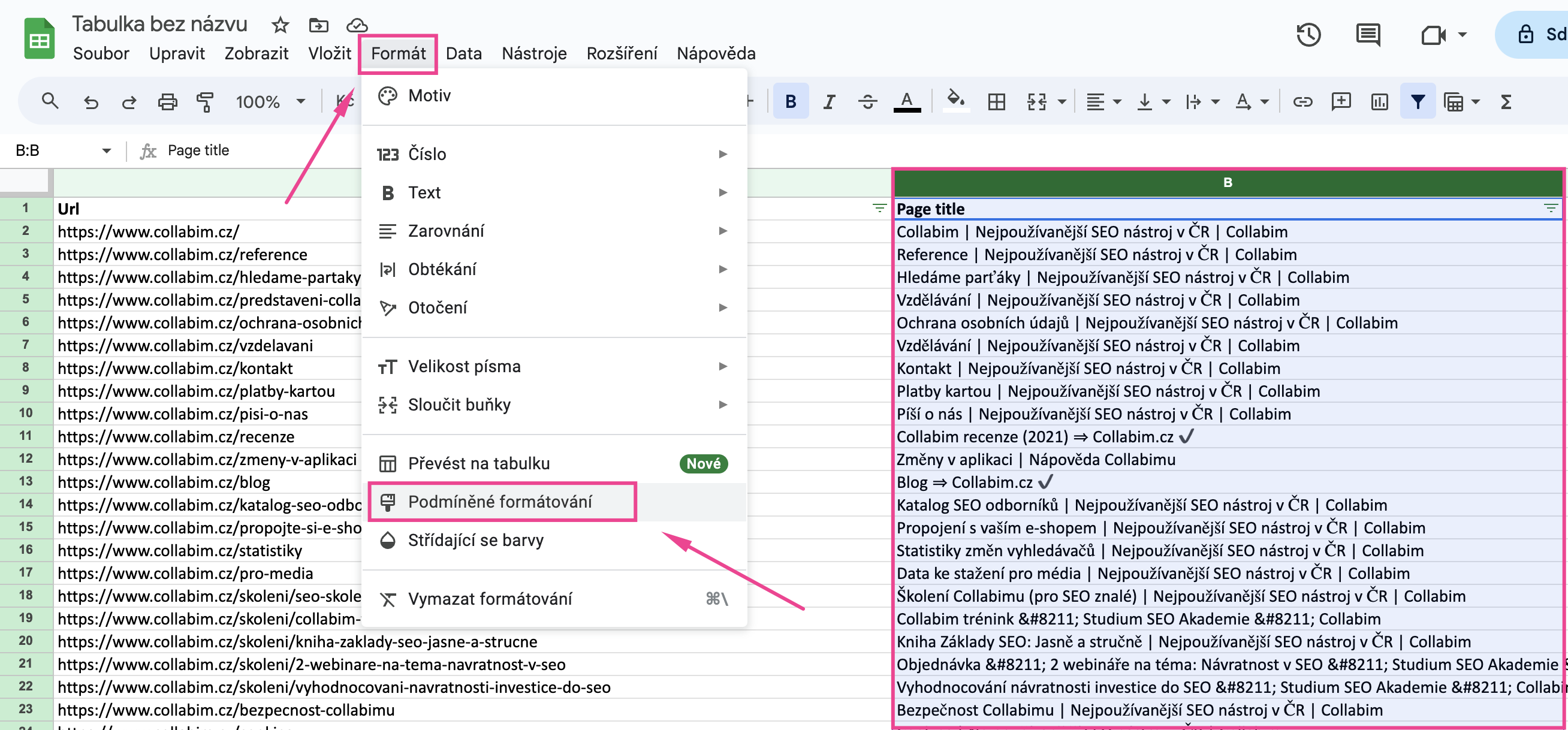
V exportu pak můžete snadno vyfiltrovat duplicity dle podmíněného formátování. Stačí označit některý ze sloupečků, který potřebujete ověřit, a v horní liště zvolit Formát -> Podmíněné formátování.
Do funkce přidáte pak podmínku pro zobrazení duplicit.
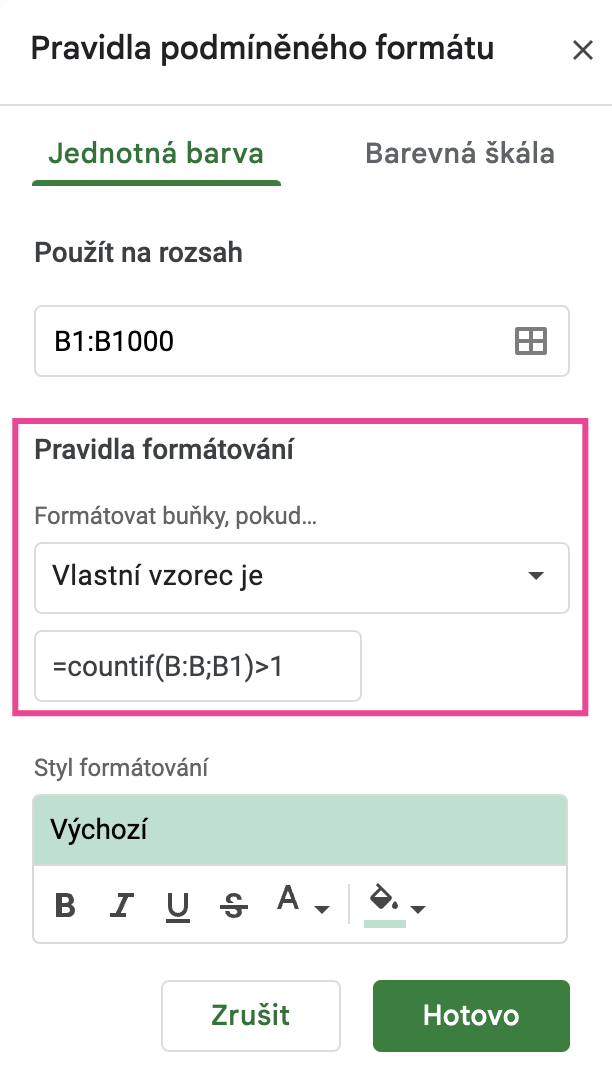
Vzoreček je např.:
=countif(B:B;B1)>1
Toto je konkrétní vzoreček pro vyznačení duplicit ve sloupci B (titulky stránek).
Pro vyznačení např. duplicitních popisků (standardně sloupec C) by vzoreček vypadal takto:
=countif(C:C;C1)>1
Zároveň můžete přidat i další podmínku “Je prázdné“. Díky tomu vyznačíte buňky, které nic neobsahují – prázdné descriptiony apod. vám totiž analýza taktéž započítává mezi duplicity, pokud chybí na více stránkách.
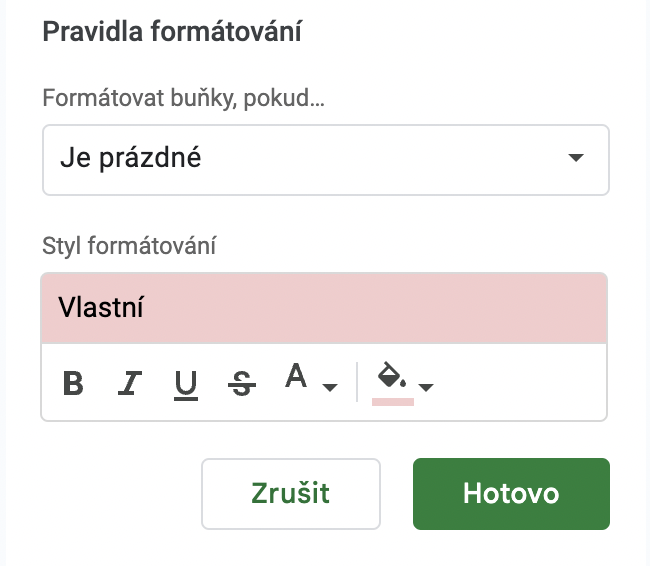
Takto ověřte, zda některé stránky nepoužívají především stejné titulky a meta descriptiony. Každá stránka by obvykle měla mít unikátní titulek i popisek.
Zatímco titulek může mít poměrný vliv na SEO, meta description slouží pro případné návštěvníky stránky (popisuje, co na stránce najdou). Nicméně i to by mohlo vaše stránky eventuálně ovlivnit, protože zavádějící titulek může vést k okamžitému opuštění stránky (anebo se uživatel na stránku nemusí vůbec prokliknout).
Rychlost načtení
Na horních grafech taktéž můžete zkontrolovat rychlost načtení stránek. Nutno upozornit, že se jedná o rychlost načtení samotného HTML kódu, který je v tomto ohledu elementární. Pokud se na stránkách nachází např. javascripty nebo obrázky, ty v této kontrole zahrnuty nejsou a vykreslení stránek tak může trvat ještě déle.
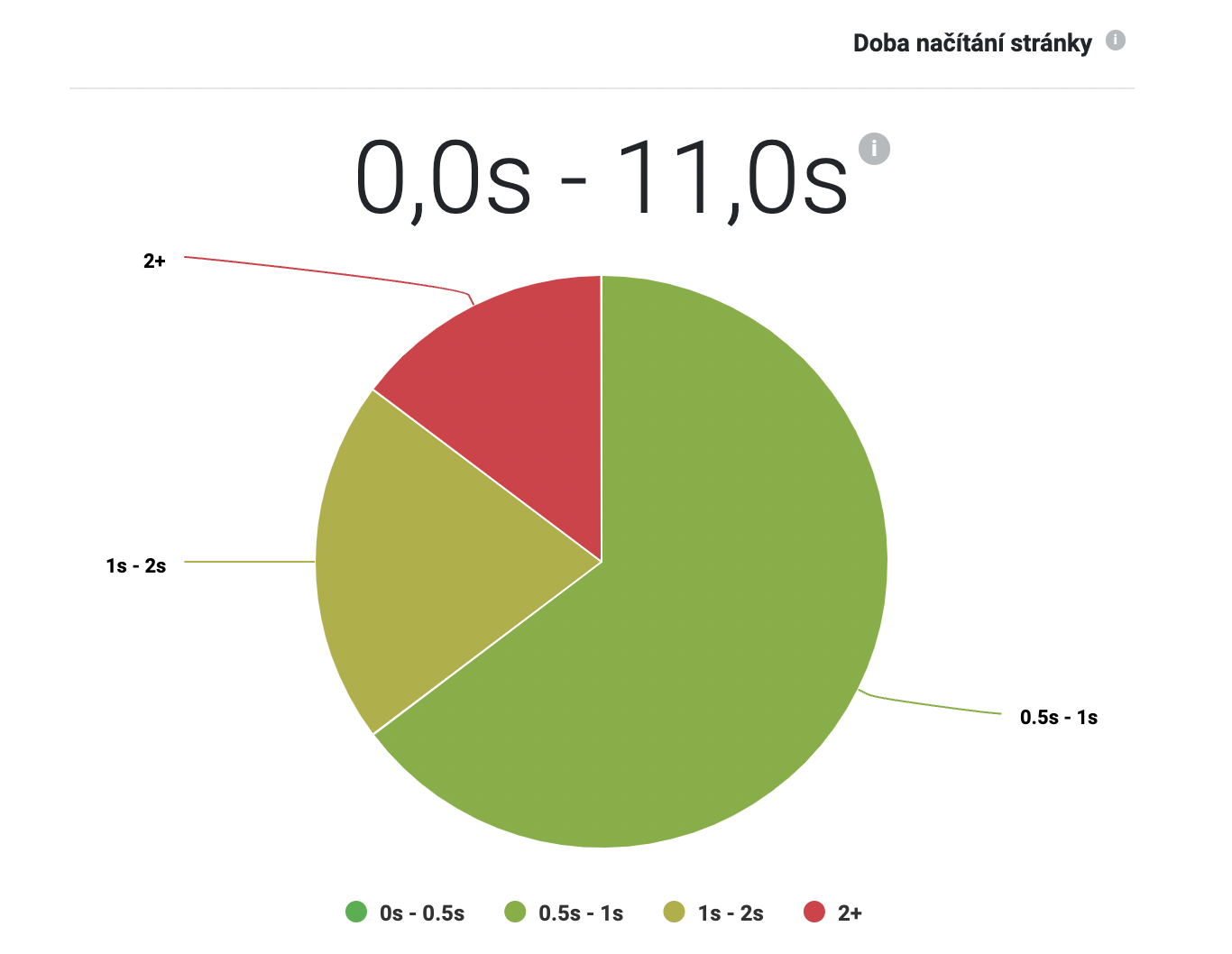
Přestože je v rámci SEO podstatný především kvalitní a unikátní obsah stránek, i rychlost jejich načtení je jedním z hodnotících faktorů. A ačkoliv je rychlost důležitá hlavně pro uživatele, pomalejší načítání může vést k větší míře opuštění stránky, což může negativně ovlivnit vaše skóre. Přijatelná rychlost načtení se pohybuje okolo dvou sekund, delší doba je obvykle nežádoucí.
V tabulce ve spodní části analýzy pak najdete časy pro jednotlivé stránky ve sloupečku “Load time“. Časy jsou zaokrouhlené na jednotky sekund. “0” tedy vyjadřuje čas “0.5 sekund nebo kratší”.
Pro podrobné filtrování opět doporučujeme pracovat přímo s exportem v Excelu nebo Tabulkách Google.
Stavové kódy stránek
Dále můžete ověřit stavové kódy stránek. V analýze najdete mmj. grafy s rozložením stavových kódů.
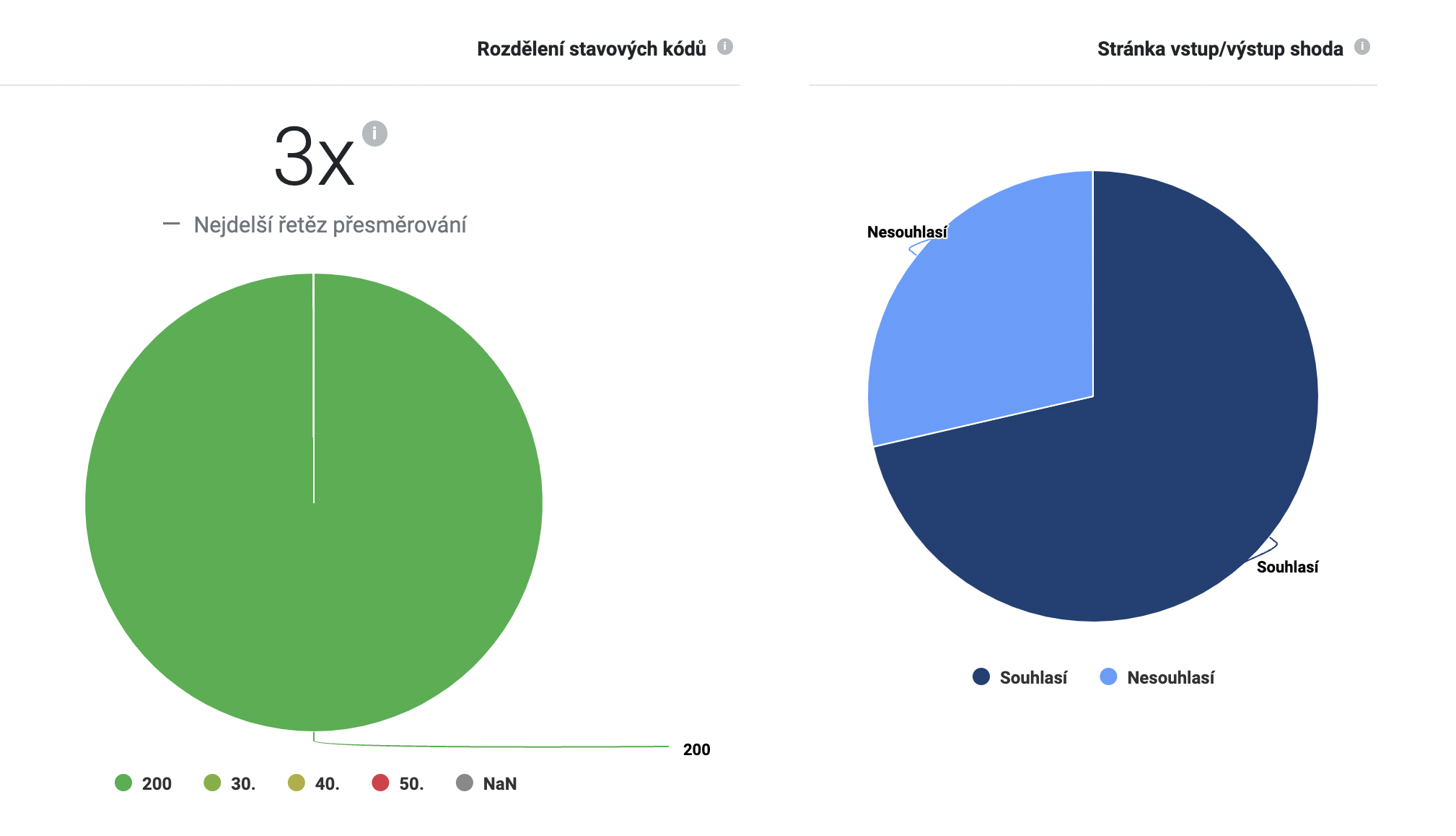
Podrobný rozpis stavových kódů každé stránky najdete opět v tabulce ve spodní části analýzy. Informaci najdete ve sloupečku “Status codes“.
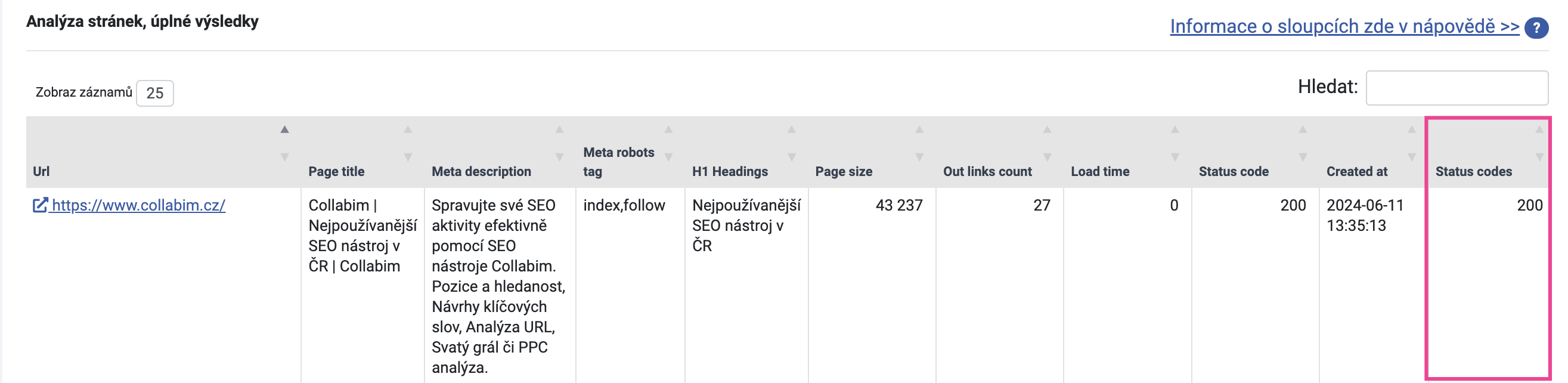
Poznámka:
Pokud v tabulce vidíte ve stejném řádku stavové kódy 3xx i 200, pak na grafu uvidíte pouze 200, který je v takovém případě primární.
V ideálním případě by stránka měla vracet kód 200. To znamená, že stránka je v pořádku.
Kódy 301 a 302 vyjadřují přesměrování a jsou také v pořádku, jsou-li nastavené správně. Jen je vhodné vyhnout se příliš dlouhému řetězci přesměrování (tzn. stránka je přesměrována na jinou stránku, ze které vede přesměrování na další stránku). Robot, který stránky prochází, většinou respektuje pouze omezený počet přesměrování v řetězu, tudíž se může stát, že než se dostane ke koncové stránce, procházení vzdá.
Zpozorněte u stavových kódu začínajících 4xx a 5xx. Stavové kódy 4xx zpravidla značí chybu na webu – velice častým problémem jsou kódy 404. Ty znamenají, že stránka nebyla nalezena. 404 je dobré se vyhnout – při změně URL nebo při odstranění stránky se doporučuje na stránku nastavit přesměrování. Tím se vyhnete 404.
Kódy 5xx znamenají chybu serveru. Objevují se ve chvíli, kdy server není schopen zpracovat požadavek na stránku. Typickými příklady jsou chyby 500 (chyba serveru), 503 (stránka je momentálně nedostupná) nebo 504 (vypršel časový limit pro požadavek na stránku). Stavovým kódům 5xx je vhodné věnovat zvýšenou pozornost.
Co dál?
Pokud jste při nastavení analýzy zaškrtli i Získávač slov z URL, můžete si ověřit, jaké výrazy se nachází v jednotlivých elementech stránky.
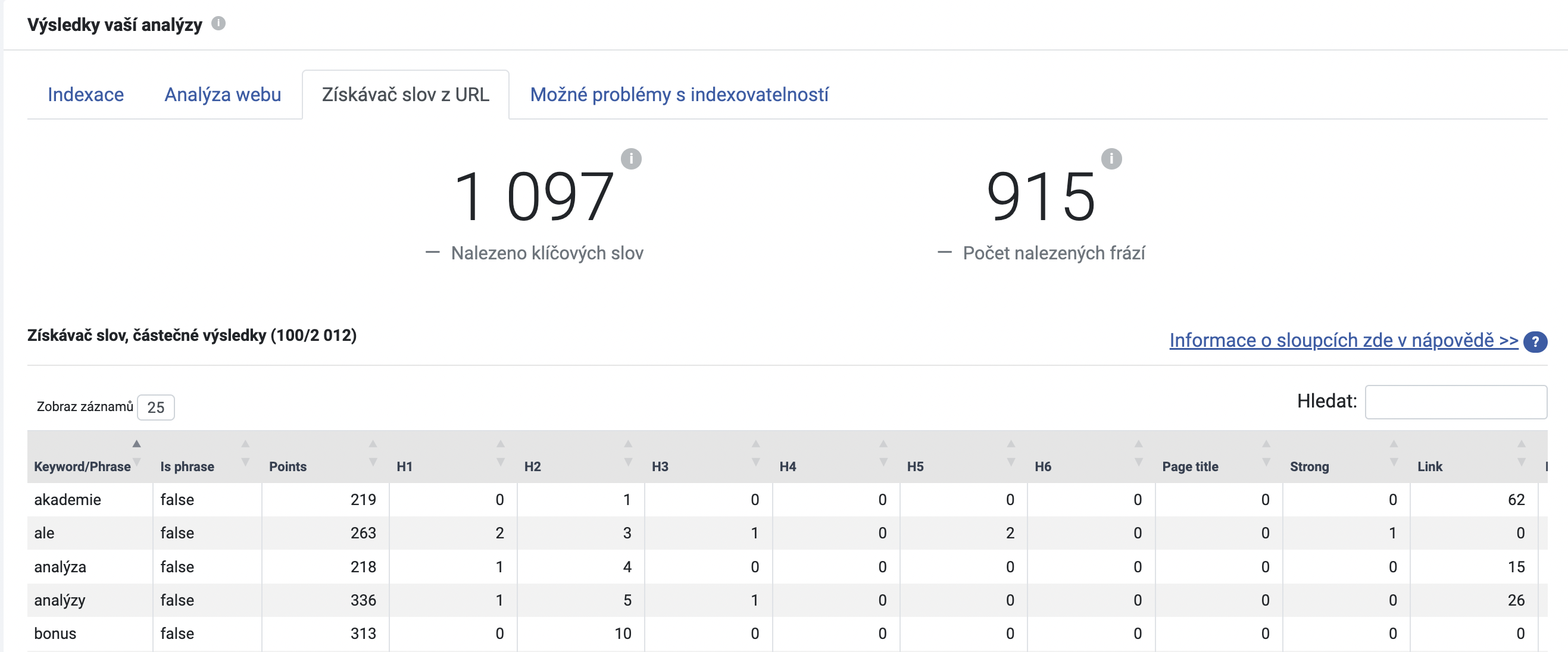
V tabulce najdete podrobný přehled, v jakém elementu stránky se nachází příslušné klíčové slovo. To vám přijde vhod zejména ve chvíli, kdy optimalizujete titulky, nadpisy, odkazy nebo třeba obrázky. Zrovna pro obrázkové SEO se jedná o šikovnou pomůcku, jelikož zde najdete informaci, zda se klíčová slova nacházejí i v alternativním textu obrázků.
Alt text (na rozdíl od titulku) totiž vyjadřuje, co na obrázku najdete. To pomáhá např. uživatelům s hendikepem rozklíčovat, co obrázek obsahuje. Ovšem alt text je podstatný i pro roboty, kteří procházejí stránky. Robot si totiž obrázek jako takový nedokáže prohlédnout a vidí ho pouze v kódu. Alt text mu tak napomáhá obsah obrázku rozluštit – a to může znamenat plusové body pro obrázkové SEO. Můžete tak zvýšit svou šanci na umístění v obrázkovém vyhledávání.
