
Problém nastal, kdy bylo na Johna Mullera dotazováno na twitteru, jak je možné, že stránka jednoho majitele webu je zaindexována i když ji má zablokovanou k indexaci v robots.txt
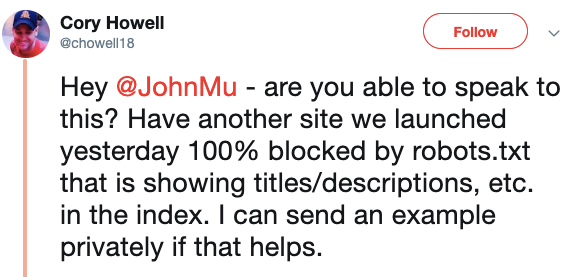
Ten odpověděl, že to, že je stránka v robots.txt nemusí znamenat, že se nezaindexuje. Pokud totiž bude Google crawlovat jinou stránku, na které je odkaz na Vaši stránku a vy ji máte zakázanou pouze v robots.txt také ji zaindexuje!
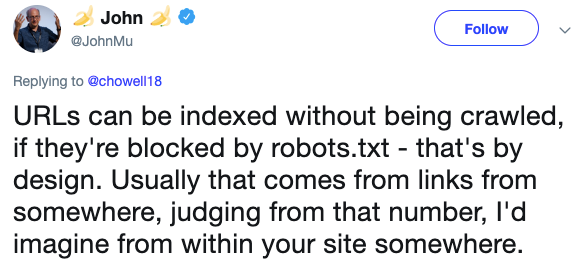
Jak funguje Robots.txt?
Často si myslíme, že Robots.txt je způsob, jak zablokovat Googlu zahrnutí stránky do indexu Googlu. Soubor robots.txt je však jen způsob, jak blokovat stránky, které Google prochází při crawlování Vaší domény.
Barry Adams o tom krásně psal na svém twitteru (volně přeloženo z anglické verze):
“Robots.txt je nástroj pro správu crawlování, nikoli nástroj pro správu indexování.
Chcete-li zabránit indexování, použijte směrnice robots meta tags nebo HTTP hlavičku X-Robots-Tag a naopak nechte Googlebot procházet tyto stránky, které nechcete indexovat, aby viděl tyto směrnice.”

Co s tím tedy?
Doporučení Johna Mullera z Google je použít meta tag noindex místo zablokování v robots.txt
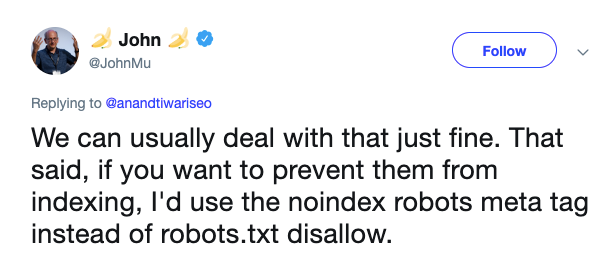
„… Chcete-li jim zabránit indexování, použil bych robots meta tag noindex místo zablokování v robots.txt.“
Robots Meta Tag Noindex
Robots meta tag noindex umožňuje, aby procházené stránky nebyly zaindexovány. Nezastavuje procházení stránky, ale zajišťuje, že stránka bude ponechána mimo index Google.
Značka metadat noindex je tedy podle Johna Mullera lepší než protokol vyloučení robots.txt pro udržení indexování webové stránky.
Pokud se náhodou vyhledavač dostane na Vaši webovou stránku přes odkaz na jiné, bude vědět, že ji nemá zahrnout do svého indexu.
Jak vložit noindex na Vaše stránky a další info najdete v officiální nápovědě Google.
Když chcete najít všechny důležité informace o robots.txt na jednom místě – k čemu slouží soubor robots.txt, jak jej vytvořit, aktualizovat i jak pracovat se sitemapou robots.txt – vše naleznete v přehledném článku Robots.txt: Kompletní průvodce, návod, tipy a rady.
